Note you don't see arXiv papers where somebody feeds in 1000 male gendered words into a word embedding and gets 950 correct female gendered words. Statistically it does better than chance, but word embeddings don't do very well.
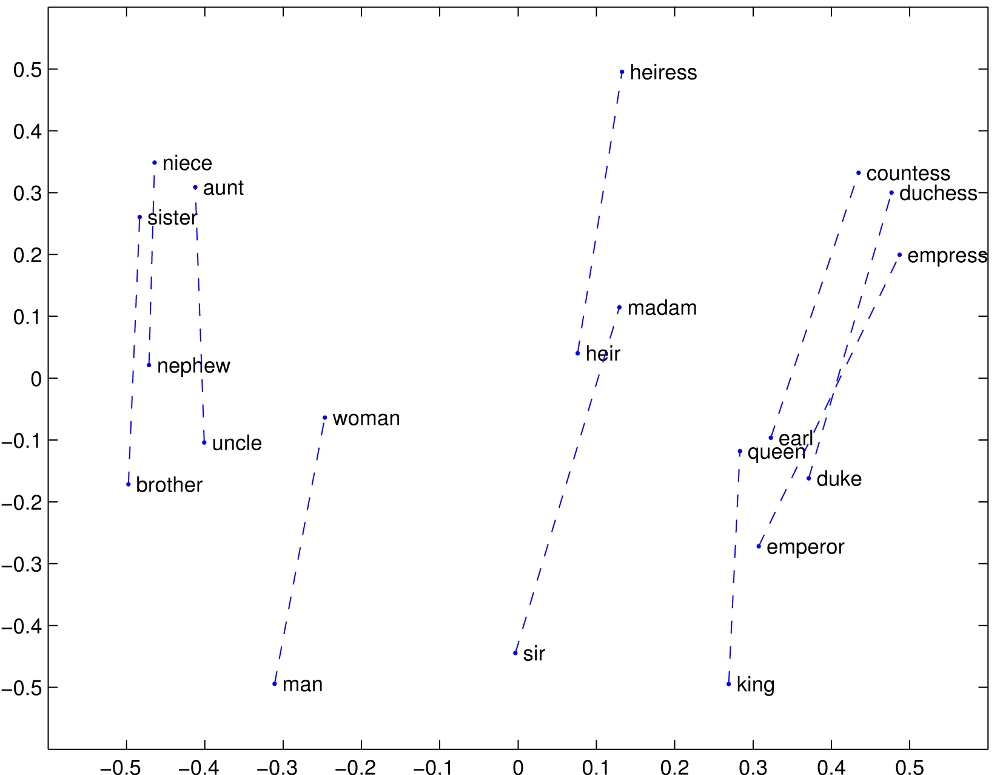
there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall. If you try experiments with N>100 words you go endlessly in circles and produce the kind of inconclusively negative results that people don't publish.
The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word. For instance you can't really build a "part of speech" classifier that can tell you "red" is an adjective because it is also a noun, but give it the context and you can.
In the context of full text search, bringing in synonyms is a mixed bag because a word might have 2 or 3 meanings and the the irrelevant synonyms are... irrelevant and will bring in irrelevant documents. Modern embeddings that recognize context not only bring in synonyms but the will suppress usages of the word with different meanings, something the IR community has tried to figure out for about 50 years.
> there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
While it would certainly have been possible to choose a projection where the two groups of words are linearly separable, that isn't even the case for https://nlp.stanford.edu/projects/glove/images/man_woman.jpg : "woman" is inside the "nephew"-"man"-"earl" triangle, so there is no way to draw a line neatly dividing the masculine from the feminine words. But I think the graph wasn't intended to show individual words classified by gender, but rather to demonstrate that in pairs of related words, the difference between the feminine and masculine word vectors points in a consistent direction.
Of course that is hardly useful for anything (if you could compare unrelated words, at least you would've been able to use it to sort lists...) but I don't think the GloVe authors can be accused of having created unrealistic graphs when their graph actually very realistically shows a situation where the kind of simple linear classifier that people would've wanted doesn't exist.
This is missing the point. What we have is two dimensions* of hundreds, but those two dimensions chosen show that the vector between a masculine word and its feminine counterpart is very nearly constant, at least across these words and excluding other dimensions.
What you're saying, a line/plane/hyper-plane that separates a dimension of gender into male and female, might also exist. But since gender neutral terms also exist, we would expect that to be a plane at which gender neutral terms have a 50/50% chance of falling to either side of the plane, and ideally nearby.
* Possibly a pseudo dimension that's a composite of multiple dimensions; IDK, I didn't read the paper.
> The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word.
In addition to being able to utilize attention mechanisms, modern embedding models use a form of tokenization such as BPE which a) includes punctuation which is incredibly important for extracting semantic meaning and b) includes case, without as much memory requirements as a cased model.
The original BERT used an uncased, SentencePiece tokenizer which is out of date nowadays.
I was working at a startup that was trying to develop foundation models around at time and BPE was such a huge improvement over everything else we'd tried at that time. We had endless meetings where people proposed that we use various embeddings that would lose 100% of the information for out-of-dictionary words and I'd point out that out-of-dictionary words (particularly from the viewpoint of the pretrained model) frequently meant something critical and if we lost that information up front we couldn't get it back.
Little did I know that people were going to have a lot of tolerance for "short circuiting" of LLMs, that is getting the right answer by the wrong path, so I'd say now that my methodology of "predictive evaluation" that would put an upper bound on what a system could do was pessimistic. Still I don't like giving credit for "right answer by wrong means" since you can't count on it.
Don’t the high end embedding services use a transformer with attention to compute embeddings? If so, I thought that would indeed capture the semantic meaning quite well, including the trait-is-described-by-direction-vector.
> In https://nlp.stanford.edu/projects/glove/ there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
Ramsey theory (or 'the Woolworths store alignment hypothesis')
A case related to that is "more like this" which in my mind breaks down into two forks:
(1) Sometimes your query is a short document. Say you wanted to know if there were any patents similar to something you invented. You'd give a professional patent searcher a paragraph or a few paragraphs describing the invention, you can give a "semantic search engine" the paragraph -- I helped build one that did about as well as the professional using embeddings before this was cool.
(2) Even Salton's early works on IR talked about "relevance feedback" where you'd mark some documents in your results as relevant, some as irrelevant. With bag-of-words this doesn't really work well (it can take 1000 samples for a bag-of-words classifier to "wake up") but works much better with embeddings.
The thing is that embeddings are "hunchy" and not really the right data structure to represent things like "people who are between 5 feet and 6 feet tall and have been on more than 1000 airplane flights in their life" (knowledge graph/database sorts of queries) or "the thread that links the work of Derrida and Badiou" (could be spelled out logically in some particular framework but doing that in general seems practically intractable)
Regarding item (2), Salton did talk about this and many systems from the early TREC times implemented them.
In my own work, I found that relevance feedback worked very well with only a few dozen judgements. See Chapter 7 starting on page 83 in my dissertation: https://arxiv.org/abs/1207.1847
Note also that the evaluation of Luduan in that chapter compared against state-of-the-art (for the time) back-of-words systems but also an early word embedding retrieval system (Convectis from HNC).
Semantic search and classification and clustering. For the first, there is a substantial breakthrough in IR every 10 years or so you take what you can get. (I got so depressed reading TREC proceedings which seemed to prove that "every obvious idea to improve search relevance doesn't work" and it wasn't until I found a summary of the first ten years that I learned that the first ten years had turned up one useful result, BM2.5)
As for classification, it is highly practical to put a text through an embedding and then run the embedding through a classical ML algorithm out of
This works so consistently that I'm considering not packing in a bag-of-words classifier in a text classification library I'm working on. People who hold court on Huggingface forums tends to believe you can do better with fine-tuned BERT, and I'd agree you can do better with that, but training time is 100x and maybe you won't.
20 years ago you could make bag-of-word vectors and put them through a clustering algorithm
I'd disagree with the bit that it takes "a lot of linear algebra" to find nearby vectors, it can be done with a dot product so I'd say it is "a little linear algebra"
Windows is better but not much. My big PC at home isn't completely reliable to attach to Bluetooth headphones, some of which might be the fault of the particular headphones, but some of which seems to be the fault of having various sorts of "virtual" drivers installed such as for Steam, MQ 3, Immersed, etc.
Yeah, I always feel surprised when people call out the Linux audio experience as uniquely bad. Meanwhile on Windows I need to jam voicemeter in the middle to separate inputs and outputs so I don't have games crashing to desktop because my bluetooth headset ran out of battery, while Mac makes each individual application implement volume control UI.
I'm still baffled by difference between Audacity on Windows and Linux. On Windows I have n+1 recording devices, where n is number of microphones, the 1 being stereo mix. On Linux I have gazillion cryptic names and I pray for each of them to even work. And neither of them is stereo mix, for such advanced feature I have to enable external mixer.
Stereo mix is a surprisingly neutral nontrivial feature. How do you mix the channels, are you okay with limitations of software mixer, do you want to hardware mix it on supported audio chipsets, what stereo mix means when you have three or more microphones?
A stereo mix is in fact trivial and roughly assumes a left right speaker arrangement. Software summing is math and is the same across digital audio workstations because math is math. Are there 3 or more microphones? doesnt matter, each mic is a mono input. trying to capture a facsimile of a perceived stereo field? use ORTF mic spacing and hard pan those mono inputs appropriately.
Stereo is just dual mono. its that simple. Summing is just math, its that trivial.
Creating a mix of multiple inputs for a stereo lr output? also completely trivial from a technical standpoint. Hardly trivial from a creative pov, but that isnt what this is about.
Windows' Bluetooth stack is an absolute dumpster fire. They trashed the perfectly good BT stack from windows 7 and apparently had an unpaid intern write the replacement.
My day job is building widgets that connect to a windows PC over Bluetooth. The situation is so bad that we're building a dedicated RF adapter so we can have a sane stack under our control.
If your program is scanning for a particular device in the background, that device will never show up in the windows BT pairing menu. I can't even imagine how that happens. Many API calls do nothing or return garbage, many BT features are just not exposed at all, despite windows clearly having that data internally.
W10 never even had BT audio sink. You could not play audio from a remote device to your PC. W7 had it and I think W11 finally got it a few years back. Linux has always had it.
Windows' Bluetooth stack is no contest the worst available on the market. It's astonishing how poor quality Microsoft products are these days.
Precisely the reason I don't understand how people can daily drive Linux on their laptop. (I say laptop because additionally: trackpad issues, Bluetooth issues, etc.)
Is it much better than 10 or 20 years ago? Yes.
Is it still annoying enough and sometimes colossal waste of time? Yes. Just use a Macbook and be done with it.
I had a midlife/mental health crisis that caused me to discover I was a schizotype, like about 5% of the population I have just a little bit of the "thought disorder" which people with schizophrenia have. No doubt this can cause attention and executive functions for certain people who will be misdiagnosed with ADHD or that the resulting social anhedonia [1] will be misdiagnosed as Autism.
You never hear about it because there was an epic confrontation between an academic who wrote forceful monographs pushing a viewpoint that was probably less true and another who organized conferences that published tentative proceedings with no clear conclusions that might have been more true [2]... the later one so schizotypy got eaten by autism. The book by the first academic changed my life, I could have skipped past the conference proceedings over and over again dismissing them as "a bunch of psychometricians screwing around with scales had a conference, so what"
I sure as hell want to erase #ActuallyAutistic everywhere I can and replace it with #SurelySchizotypal
[1] somehow teachers and other professional adults can't see what is wrong with you but the other kids in your kindergarten class can't unsee it so you'll be a bully magnet no matter what
[2] for which "nothing more to see here move on folks" would arise to about as many people as who might wonder how posh the conference center was
was repeated I’m sure most civilizations could figure out that it was a raster but if it is sent once the odds are awful. Past that what would they understand? If we sent it today we wouldn’t put Pluto on the planet list. Maybe 10k years from now there are a trillion people living on Ceres and it would be unthinkable to waste volatiles to fly to some dry spot like Earth and we’d again send a different message.
Figuring out the raster structure of NTSC television seems straightforward and even if they never figure out how color was encoded I think they’d still get a lot out of it even if their senses were different and they couldn’t “watch” TV. I am skeptical though that anybody would figure out how to decode the current ATSC signals, never mind the new ATSC 3 standard or 4G or 5G wireless signals that people stream TV over.
Who says raster is a universal way to serialize an image? Who says a serializable image is probably rectangular? Who says the notion of serialization is a universal? What are alternatives to any of these? Can we exhaust the alternatives? (Finally, a question that has an answer: no.) Who says sampling or quantization are universals?
In order to know what they might do, let alone how, we would first have to know why. And their why is not going to be our why. Anybody's why is determined by what they are right up against. (This is why evolution immiserates, because it guarantees that we spend most of our time at the boundary of our envelope.)
I'll argue that serialization is universal, there are so many cases in technology where you can scan something with a rotating or moving platform, it takes rather sophisticated electronics to implement "holographic" protocols such as the FFT, Borrows-Wheeler Transform, Deep Interleaving, Forward Error Correction, etc and I just don't see how you get to the place where you can build that kind of thing without breaking things down logically into systems that use serialization.
I am sure that aliens who can build computers know about the halting problem but they probably formulate it differently. [1] I doubt they have 8-bit bytes. They probably, like us, skipped Indium Phosphide, Gallium Arsenide and such for Silicon, but I'm not so sure about that.
[1] Turing started out with a line of though that seems oddly disreputable now: we know most of Cantor's phony numbers (that we call the "reals") don't have names [2], but some of them, like π do. Is the difference between the named and nameless ones that we can program a Turing machine to print out the named ones?
Zoom out. Remember all the technologies that have been backed into wrong-way-first. Future humans, leave aside aliens, will be unable to distinguish between the engineering drawings of anything that has moving parts and the cartoons of Rube Goldberg. Remember Haldane (the quote is also attributed to Jeans, Hoyle, Eddington, and various others): "The Universe is not only queerer than we suppose, but queerer than we can suppose."
(The one thing that they will have, even if to their distaste, is powers of 2.)
ETA: If Turing was trying to make a distinction between the finiteness of the symbol for (say) the square root of three, versus the infinitude of the process that must be executed to evaluate it, that would be not so much disreputable as nonsensical. He was fond of setting up straw men; let us suppose that this was one of them.
I see the difficulty of communications as the X factor here which is not so unknown. Our telescopes are not good enough to see a civilization like ours even on Alpha Centauri. It’s thought now we could observe a civilization like ours around a single star if we launch a probe past 500 au to the Sun’s gravitational lens. NASA wishes they could do that but it looks out of reach for now.
A ‘type ii’ civilization which could disassemble terrestrial planets could point a big-ass laser at us which we could see but maybe they don’t all (or ever) get that big. And they have to be motivated to do it.
If you want to visit another star you have to stop at the destination which is almost as hard as getting to speed but if you want to communicate a message which cannot be misunderstood you could bomb a planet with relativistic speed projectiles. Now maybe the average type ii civilization would not do that but maybe the fear that another one could so that might motivate a preemptive attack. It adds up to it being risky to attempt contact so why try?
to a star cluster 25,000 light years away. Even if somebody in that 300,000 star cluster has a telescope pointed in the right direction and the right time we could be long gone by the time they get a message back to us or maybe we forgot we sent it or now most of us live on another star…
We wouldn't be able to see, but radio detection is definitely possible. A type II civilization would possibly leave technosignatures we could detect with optical telescopes as well.
As a Pythoner the most direct value I get out of types is the IDE being smart about autocompletion, so if I'm writing
with db.session() as session:
... use the session ...
I can type session. and the IDE knows what kind of object it is and offers me valid choices. If there's a trouble with it, it's that many Pythonic idioms are too subtle, so I can't fully specify an API like
not to mention I'd like to be able to vary what gets returned using the same API as SQLAlchemy so I could write
collection.filter(..., yield_per=100)
and have the type system know it is returning an iterator that yields iterators that yields rows as opposed to an iterator that yields rows. It is simple, cheap and reusable code to forward a few fetch-control arguments to SQLAlchemy and add some unmarshalling of rows into documents but if I want types to work right I need an API that looks more like Java.
If I understand correctly, you can do this with overloads. They don't change the function implementation, but you can type different combinations of parameters and return types.
But the amount of money going by is so huge they can take a tiny percent of it to pay their server bills.
Dynamic languages in large systems have been controversial since there have been dynamic languages. It was routine for heroic AI systems of the golden age (1980s) to be prototyped in Lisp and then be rewritten in C++ for speed. You'd hear stories about the people who wrote 500,000 lines of Tcl/Tk to control an offshore oil drilling rig and the folks who think "C++ is a great language for programming in the large" but who don't seem to mind having a 40 minute build.
> But the amount of money going by is so huge they can take a tiny percent of it to pay their server bills.
I think that's an oversimplification that doesn't do justice to the complexity or difficulty of the issue. Both sides of the argument can make a really good case.
Slow programs (due to language or other factors) increase server costs, but that's only part of the problem. They also increase operational and architectural complexity, meaning you spend more time, effort and specialized expertise on these secondary effects. Note that some of that shimmers through in the article, mentioning "CI flakiness": It's probable that the baseline performance and its effects is a factor there. Performance has a viral effect on everything, positively or negatively. They also complain about async not being a part of the story here, which is also a performance issue.
On the other hand, this shop has hundreds of developers. That means deep expertise, institutional knowledge, tooling, familiarity with each line of code and a particular style that they follow. Ruby is also a language that is optimized for programmer experience, and is apparently a fun language to work with. All those things are very essential investments, individually and as a whole. Then we can assume that they use Ruby like most glue languages are used and either write C/C++ modules where appropriate or attach high performing components into their architecture (DBs, queues, caches etc.)
The reason I'm harping on this point is because I think it's important to acknowledge a more complete reality than the "hardware is cheap, people are expensive" statement. I assume it's very likely a throwaway line and not a hill you'd die on. But it masks two interesting and important things: Performance matters a lot and impacts cost transitively, but people and culture ultimately dominate for very good reasons.
I think you could have very happy devs working on a system like Stripe in either Java or Ruby, the choice of language is less important than everything else.
Personally I would judge an engineering manager on how seriously they take issues with the build. The industry standard is that a junior dev having trouble with the build is told he's on his own, the gold standard is that he gets a checklist and if the checklist doesn't work it is treated as if the dev had said "I have cancer".
A fast language can be slow to build. [1] If you were really designing a system for long term maintainability fast and sensible tests and solid CI would be determining factors. The only velocity metric which needs to be measured is the build time.
At the moment I have a side project I'm doing which is a port of the arangodb API to postgresql intended to bring a few arangodb applications into the open source world. I test at the level where I make a new postgres db and do real operations against it because I really need to do that to soak up all the uncertainty in my mind, never mind test the handful of stored procs that the system depends on. I have 5 big tests instead of the 300 little tests I wish I had because it takes 0.2s to set up an tear down the fixtures and if the tests take too long to run that's really a decision that I'm not going to do any maintenance on the thing in the future.
I am working on a React system which is still in an old version where test frameworks can't tell if all the callbacks are done running which means practically I don't write tests because even though I'm a believer in tests, it already takes 50 sec to run the test suite and frequently as much time to update tests as it takes to make changes. Had I been writing tests at the rate I want my tests would take 500 sec to run.
[1] Though I'd argue that performance concerns are one reason we can't have nice things when it comes to flexible parsers and metaprogramming; Python's use of PEG grammars has so far fallen so short of what it should have been because of these concerns, no unparser to go with the parser, no "mash up SQL or some other language into a certain slot in the Python grammar"
{kind=link}
In
https://nlp.stanford.edu/projects/glove/
there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall. If you try experiments with N>100 words you go endlessly in circles and produce the kind of inconclusively negative results that people don't publish.
The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word. For instance you can't really build a "part of speech" classifier that can tell you "red" is an adjective because it is also a noun, but give it the context and you can.
In the context of full text search, bringing in synonyms is a mixed bag because a word might have 2 or 3 meanings and the the irrelevant synonyms are... irrelevant and will bring in irrelevant documents. Modern embeddings that recognize context not only bring in synonyms but the will suppress usages of the word with different meanings, something the IR community has tried to figure out for about 50 years.
reply