Note you don't see arXiv papers where somebody feeds in 1000 male gendered words into a word embedding and gets 950 correct female gendered words. Statistically it does better than chance, but word embeddings don't do very well.
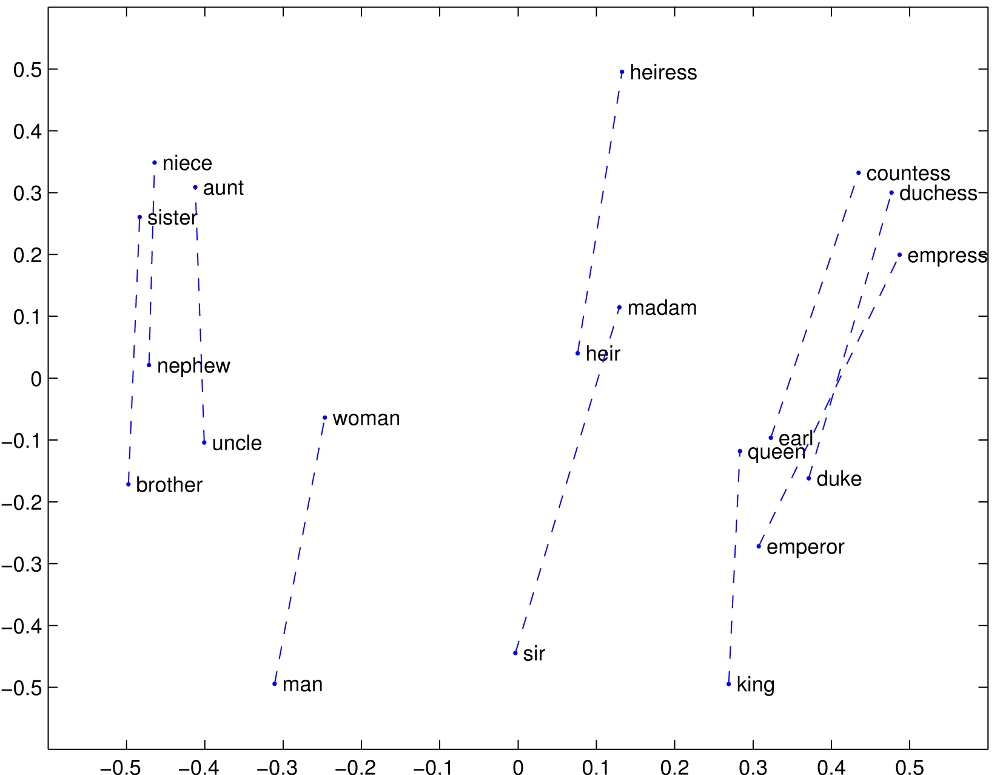
there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall. If you try experiments with N>100 words you go endlessly in circles and produce the kind of inconclusively negative results that people don't publish.
The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word. For instance you can't really build a "part of speech" classifier that can tell you "red" is an adjective because it is also a noun, but give it the context and you can.
In the context of full text search, bringing in synonyms is a mixed bag because a word might have 2 or 3 meanings and the the irrelevant synonyms are... irrelevant and will bring in irrelevant documents. Modern embeddings that recognize context not only bring in synonyms but the will suppress usages of the word with different meanings, something the IR community has tried to figure out for about 50 years.
> there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
While it would certainly have been possible to choose a projection where the two groups of words are linearly separable, that isn't even the case for https://nlp.stanford.edu/projects/glove/images/man_woman.jpg : "woman" is inside the "nephew"-"man"-"earl" triangle, so there is no way to draw a line neatly dividing the masculine from the feminine words. But I think the graph wasn't intended to show individual words classified by gender, but rather to demonstrate that in pairs of related words, the difference between the feminine and masculine word vectors points in a consistent direction.
Of course that is hardly useful for anything (if you could compare unrelated words, at least you would've been able to use it to sort lists...) but I don't think the GloVe authors can be accused of having created unrealistic graphs when their graph actually very realistically shows a situation where the kind of simple linear classifier that people would've wanted doesn't exist.
This is missing the point. What we have is two dimensions* of hundreds, but those two dimensions chosen show that the vector between a masculine word and its feminine counterpart is very nearly constant, at least across these words and excluding other dimensions.
What you're saying, a line/plane/hyper-plane that separates a dimension of gender into male and female, might also exist. But since gender neutral terms also exist, we would expect that to be a plane at which gender neutral terms have a 50/50% chance of falling to either side of the plane, and ideally nearby.
* Possibly a pseudo dimension that's a composite of multiple dimensions; IDK, I didn't read the paper.
> The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word.
In addition to being able to utilize attention mechanisms, modern embedding models use a form of tokenization such as BPE which a) includes punctuation which is incredibly important for extracting semantic meaning and b) includes case, without as much memory requirements as a cased model.
The original BERT used an uncased, SentencePiece tokenizer which is out of date nowadays.
I was working at a startup that was trying to develop foundation models around at time and BPE was such a huge improvement over everything else we'd tried at that time. We had endless meetings where people proposed that we use various embeddings that would lose 100% of the information for out-of-dictionary words and I'd point out that out-of-dictionary words (particularly from the viewpoint of the pretrained model) frequently meant something critical and if we lost that information up front we couldn't get it back.
Little did I know that people were going to have a lot of tolerance for "short circuiting" of LLMs, that is getting the right answer by the wrong path, so I'd say now that my methodology of "predictive evaluation" that would put an upper bound on what a system could do was pessimistic. Still I don't like giving credit for "right answer by wrong means" since you can't count on it.
Don’t the high end embedding services use a transformer with attention to compute embeddings? If so, I thought that would indeed capture the semantic meaning quite well, including the trait-is-described-by-direction-vector.
> In https://nlp.stanford.edu/projects/glove/ there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
Ramsey theory (or 'the Woolworths store alignment hypothesis')
{kind=link}
In
https://nlp.stanford.edu/projects/glove/
there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall. If you try experiments with N>100 words you go endlessly in circles and produce the kind of inconclusively negative results that people don't publish.
The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word. For instance you can't really build a "part of speech" classifier that can tell you "red" is an adjective because it is also a noun, but give it the context and you can.
In the context of full text search, bringing in synonyms is a mixed bag because a word might have 2 or 3 meanings and the the irrelevant synonyms are... irrelevant and will bring in irrelevant documents. Modern embeddings that recognize context not only bring in synonyms but the will suppress usages of the word with different meanings, something the IR community has tried to figure out for about 50 years.