Forum post from Dan Kaminsky, co-founder of WhiteOps[1][2]:
"Dan Kaminsky here, my apologies for kicking up a ruckus. This is part of a bot detection framework I've built at White Ops; we basically are able to detect browser automation using resources exposed in JavaScript. Nothing dangerous to users -- or we'd go file bugs on it, which we do from time to time -- but it does provide useful data regarding post-exploitation behavior. Happy to jump on a call with anyone concerned or worried; I'm over at dan@whiteops.com."
Wow, so if I'm reading that right, they wrote a tracker that generates a new request every 5 seconds? These scumbags are ruining the web. And they wonder why people use ad blockers...
This looks like it's trying to exercise every dark corner of the user's browser in order to ensure that the browser is a real, eyeball-facing browser and not just a URL fetcher, PhantomJS/SlimerJS, or a clickjacking plugin being used to fraudulently click ads.
I think it's easy to see both sides here: tools like this are a powerful way to detect and combat botnets and click fraud, but if/when weaponized they're also a form of browser fingerprinting which is a nasty way to ruin anonymity across the web.
IMO there are a lot of bigger targets on the Taxonomy of Bad Internet Things: malware-serving bottom-tier ad networks, "wrapped download" sites, clickjacking, and especially cross-site correlative "analytics" companies come to mind as being more sinister to privacy than Dan Kaminsky going botnet hunting.
I'd argue that collecting unique information from your browser does not necessarily make you "the bad guys". Lots of legitimate anti-fraud products used on bank/investment websites collect that information and detect/prevent account takeovers before fraudsters can steal money and identities, for example.
What can make it bad is:
1. What you do with that information.
2. Who or what you share it with.
3. How far your reach extends.
An ad network which can place that code on multiple websites can put itself in a position of power and track devices, and thus browsing habits, of individuals.
However, if you have fingerprinting code only on your own website, and don't share that information with any other people/companies/websites, and use it solely to detect malicious bots, users, and behaviors, then I don't really think it's bad. It's like the difference between a gas station owner pointing a closed circuit camera at the door and someone flying a surveillance drone over a whole state. Both are surveillance, but one kind is much less ethical.
Yeah, I ran into a site a while back that was clever enough to spot that I wasn't using a browser.
So I did, Selenium allows you to automate a real browser and capture the responses, hell if need be you can create a fake profile with Chrome and make it completely indistinguishable.
EDIT: explanation, it was a video tutorial site for one of the technologies I use, each video had a download link but it had no way to batch downloads for offline use, scraping it with normal tools didn't work since it was doing UA and other sniffing so I whipped up a python script to control chrome to authenticate, sign in get the cookie and then pulled the unique to that session download link for each video, since I'm not a dirtbag I set the time between downloads to 30 minutes (average video is 15 minutes) and left it running for 24 hours to get the ones I wanted.
Selenium allows you to automate a real browser and capture the
responses, hell if need be you can create a fake profile with Chrome
and make it completely indistinguishable.
Are there no headless browsers that let you accomplish the same thing? Honest question...
I've used Selenium, but I just assumed that headless browsers were exactly: real browsers minus the UI.
Quite possibly but I use selenium extensively during dev to automate boring tasks (filling in forms over and over is boring) as well as for integration and functional testing.
So I had a hammer and the problem looked like a nail. ;)
This looks like it's trying to exercise every dark corner of the user's browser in order to ensure that the browser is a real, eyeball-facing browser and not just a URL fetcher, PhantomJS/SlimerJS, or a clickjacking plugin being used to fraudulently click ads.
It sounds like it would be quite easy to circumvent just by running a real browser... especially with lightweight VMs.
Shouldn't it be impossible for a website to determine what files exist or do not exist on a local machine? That sounds like a serious security problem. It seems that no non-file:// site should ever be allowed to load a file:// resource, much less query the element for its size or error state afterward.
It is scenarios like this that make me unhappy with net neutrality principles that suggest all packets are equal.
We are still very early in the age of the Internet. People are sending all sorts of trashy traffic. There is ample opportunity to optimize but net neutrality means we have to treat it all the same. It's nuts.
What problems are caused by browser automation? Slightly more on point, what issues might the NYT be seeing that detecting browser automation is the sensible solution?
I deal with this all day every day working with advertisements. A lot of money is spent trying to detect "bad users" and/or "bots" (usually the same thing). I'm talking hundreds of thousands of dollars, if not millions a year in some cases.
I'm actually working on developing a system to track browser analytics and usage to detect if it's a person on the other end or a bot.
The quick solution of course would be to have a captcha when viewing ads on sites so the advertiser could confirm it's actually a legitimate user, but there are users that are doing everything they can to not be tracked/or view ads, so what incentive do they have to confirm they are a human just so they can be targeted for advertisements? That's why there are companies trying to work behind the scenes to see if the browser is a legitimate session, or a bot session.
Companies looking to buy advertisement space are really honing in now on bots, because it's become such an issue where server farms are set up that will automate views on pages to inflate profits, or like in the case of the company that runs this script on NYtimes, to see if the user is viewing the page through a legitimate viewing session, or if the user is running software in the background of their computer pushing page views automatically.
I could probably talk all day long with this, but advertising is a huge HUGE market. There is little to no day-to-day talk of the users that are running ad block on their computer, it's a low percentage of the actual users we are running into. The large talk is the people that have created botnets of hundreds of computers to push thousands of fake impressions and how to handle that.
Just a friendly reminder for anyone using uBlock Origin on Chrome or Firefox that you can now configure it to prevent webRTC from leaking your real IP:
NoScript mitigates the problem because WebRTC won't work with scripts blocked but I'll still have to disable the plugin to make it work on legitimate sites. It's annoying and I'd prefer a browser permission popup along the lines of what has been suggested in other posts here.
enabling the option in ublock origin, my local IP would not show but my "Public" IP address still showed.
decided to checkout what options are in chrome://flags for webrtc (use to be enable/disable for webrtc but now thats restricted to just android).
found this other option in the flags, chrome://flags/#enable-webrtc-stun-origin
Enable support for WebRTC Stun origin header. Mac, Windows, Linux, Chrome OS, Android
When enabled, Stun messages generated by WebRTC will contain the Origin header.
i enabled it, my public IP no longer shows on that site.
doesnt matter if i disable/enable ublock, my public IP never shows on that site with that chrome flag enabled.
any idea what that flag actually does? and repercussions leaving it enabled?
That is odd... for me (Firefox on Windows), enabling that option completely removes the `RTCPeerConnection` property from the global object, and any script that tries to use it fails with `TypeError: RTCPeerConnection is not a constructor`.
If you want to hide the IP you're connecting from, and you want to use IPv6, then you have to find an IPv6-enabled VPN (or make one yourself with a cheap vps).
The major use case for webrtc ip leak blocking is preventing leaking of rfc1918 IPs (or link/site-local IPv6 addresses) and preventing leaking of alternate LAN and alternate public IPs.
For example, if you web browse through a VPN, this webrtc functionality will by default reveal not only your public VPN exit IP, but also your VPN rfc1918 ip, and also your real rfc1918 ip, and your primary, non-vpn public IP. All in the name of better connectivity for webrtc. It's horrible.
I don't understand why webrtc does this. How does revealing non-global addresses help improve (edit: reliably improve) connectivity? Those addresses aren't guaranteed to be globally unique, so if you have two webrtc app users on the same non-global netblock, so what? Even if they have the same public IP, it's not guaranteed that they can talk to each other with their non-global addresses; they could be on different (isolated) internal networks. So the app will be blindly trying to connect to random internal ip addresses. Sounds fun for NIDS.
It's necessary if the NAT device doesn't support hairpinning. Unfortunately, historically many didn't, so users couldn't connect to other users on the same NAT using their public IPs, even with techniques that worked fine for connecting to other identical NAT setups elsewhere.
It's not safe to assume that multiple clients behind the same public IP are on the same LAN. At my office, wired and wireless clients NAT to the same public IP, despite being on different subnets.
Plus, thanks to IPv4 depletion there might be multiple layers of NAT involved, because ISPs are having to deploy carrier-grade NAT.
You only send a broadcast to attempt to reach the other party. If it does not work, you fallback to the public IP. This is sorta what ICE does already.
>and your primary, non-vpn public IP. All in the name of better connectivity for webrtc. It's horrible.
I don't see how WebRTC could do this if you're actually routing 0.0.0.0 to your VPN, which I think is how a lot of people use VPNs when they're the kind you toggle on and off. Are you aware of a way it could get your non-VPN public IP even in those cases?
I use pfSense VMs as VPN gateways. It's easy to create nested VPN chains through virtual networking. The VM that I'm currently using has never seen my ISP-assigned IP address. I also have IPv6 disabled everywhere.
With ipv6 there are the privacy extensions[1] for SLAAC which will assign your computer a new v6 address from your network prefix in a regular interval.
This is enabled by default on windows, osx and some linux systems.
But I do wonder whether webrtc can find your other v6 addresses, a host often has more than one.
Yes, sharing IP addresses is needed for P2P communication to work so enabling this blocking option would also block legitimate uses of WebRTC such as video chat (e.g. https://talky.io , https://appear.in , etc.) and low-latency data sharing.
A whois on the domain serving the offending javascript leads to White Ops[0], who seems to sell tools to protect against Ad Fraud. So I'm guessing this is part of their fingerprinting system, to determine whether I am a human or a bot.
I believe that WebRTC, just like JavaScript, should be disabled by default and enabled only on sites that you really trust and need it; and in the case of WebRTC, the argument is much stronger since its use-case is so specific.
I'm sure someone could do better than this but here is a first try at a suitably informative prompt:
$site_name wants to use WebRTC.
WebRTC allows voice calling, video chat, and P2P file
sharing, but can also be a privacy risk. We recommend
allowing WebRTC only on sites that you expect to use
such features on.
[Link to learn more]
Allow WebRTC for $site_name?
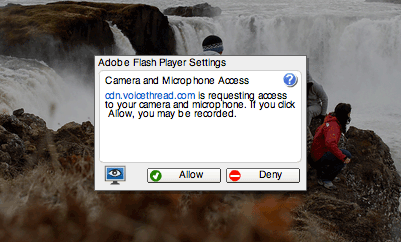
Something like Flash's audio/video access prompt would also be a good idea:
Security dialogs like this don't work. No one reads them and in this case it isn't even asking users to make a decision they can understand. It's hard enough to have the right UI when a user is on a site with a broken SSL cert which is really straightforward.
It's not; I think you're parsing 'expect to use' differently than intended.
"sites that you expect to use such features on"
This means "sites on which you expect to use such features"
Not "sites where you expect them to use such features"
The preposition is key to having you be the one using, not the site. It doesn't have to go on the end, perhaps, and you could rewrite the sentence without that preposition, but simply removing it would leave you with an entirely different meaning.
For access to the mic and camera, that's basically what it does already: prompt for permission.
So what you're really asking for is "can the web app know my non-NATed IP address if I'm behind a NAT and my non-VPN IP address if I'm behind certain kinds of VPNs"?
Are the rest of us who don't use Tor going to have our lives ruined? Certain data such as social security numbers and bank passwords are obviously critical, but I wonder what drives this seemingly excessive paranoia. For example, who cares about your IP address in general purpose web situations? Obviously if you're doing sql scans or pentesting obscuring your location is extremely important, but I'm not convinced of the benefit of high paranoia in most use cases. Reasonable paranoia sure, but going so far as to Tor everything?
For me it's more about the fact that companies are collecting too much data and not anonymizing it properly or securing it properly. I doubt Walmart, or whomever is going to do much more than send me annoying emails or postal mail at worst.
What I'm more concerned about is things like criminals obtaining the info and realizing my personal machine might be a good target for some reason. Or some company selling the data, which eventually gets to a healthcare company that is able to connect my browser history to my name and start denying me coverage or marking me as "potentially high risk" because I looked up the wrong thing, or things like that.
I haven't gone as far as using Tor, but I block cookies from 3rd parties, use ad blockers and browse entirely in private mode until I'm forced not to by some lame web site. After I'm done, I delete as many tracking things as I can and turn private mode back on.
I said this when the vulnerability/bug/whatever you want to call it was posted here: I use the same method for fraud detection, and it works unreasonably well.
That said, I'd rather there be permissions surrounding WebRTC, but my clients are happy.
It's easy to gather local IP addresses. WebRTC is just one of dozens of methods of doing this. Others include various DNS tricks, reverse TCP traceroute, <img> tag tricks, JavaScript/XMLHttpRequest tricks, etc. Private IP addresses (10.x.x.x) are not all that private.
Look into browser fingerprinting, among other things. This is a losing battle.
I am deeply pessimistic about the potential for tracker-blind browsing without extraordinary measures. A simple plugin or cookie rules simply do not and cannot cut it.
There are just umpteen million ways to fingerprint a device. What plugins do you have installed? What is your font list? What can be deduced about your device's make/model/revision from things like HTML feature support? Then you have WebGL and other technologies that potentially allow for hardware fingerprinting via various methods, slight differences in JS performance revealing things about your JS runtime engine's revision (JIT differences, etc.). Don't even get me started on all the myriad things you can do with TCP, ICMP, network latency, geo-ip, etc.
Anything less than onion routing (Tor and friends) combined with a high-isolation virtual machine or separate hardware device and a browser with no persistent state whatsoever is probably provably inadequate to protect you from fingerprinting or tracking. Any un-obscured network path back to you, access to any form of non-generic local hardware or storage, or persistent state equals fingerprinting/tracking hacks.
It's like using simple XOR for "encryption" and then saying "well, it's better than nothing." Yeah, maybe it's a nano-something better than nothing but it's basically nothing. You might as well not even bother.
Personally I think privacy is dead dead dead dead dead and we need to start talking seriously about what kinds of new political mechanisms and safeguards we need to mitigate abuse. This is a political problem and does not have a technical solution that doesn't come with a lot of cost -- e.g. the enormous performance overhead of onion routing and the inconvenience of secure computing environments. 99.999% of users are not going to do any of that stuff and never will.
Sadly so. A little while back (maybe 2013 or 2014?), I recall reading of a conference where one of the Google co-founders touched on that very point - that there were something like 90 factors they record, to help identify you uniquely for tracking. Unfortunately, trying to locate that quote hasn't proven fruitful - if anyone can pinpoint the talk I'm thinking of, I'd be grateful.
Privacy is not a boolean. EU-style data protection regulation in the US could substantially improve the situation against private company level privacy threats.
The TOR Browser Bundle is a great example of what can be done. I think it's actually pretty effective, especially with the more paranoid modes. It doesn't provide font lists, doesn't run JS, doesn't expose WebGL, picks one of a few standard screen sizes, etc.
I'd agree though that preventing general purpose browser fingerprinting is pretty much dead.
Can they grab local IPv6 addresses using this? While a huge number of computers are going to be on 192.168.0.1, their IPv6 address could actually be unique, making user fingerprinting easier.
Yes they can grab the IPv6 address but IPv6 has a privacy extension to cater for this. It will alter your local IPv6 address periodically. You could configure it to update every hour and effectively they'd be thinking you were a new PC on the network.
IPv4 you'd have a small range of IP addresses but with IPv6 you can have a different IPv6 address each hour if you so choose.
If you go read the bug you linked to, you can see that we added code to Chrome to specifically make this extension possible. It's in many CLs, but here is an example of one:
WebRTC's protocols are actually standardized at the IETF in the RTCWEB working group, by a large number of people. The W3C is in charge of the Javascript API (which is actually what people are complaining about here), again with a lot of contributors (yes, Google was bigger here).
But this part is the silly anti-NAT behaviour, most likely ICE, right? It has a questionable idea of finding all local IPs, so you can enjoy the benefit of your RTP getting sent over VPN channels and whatnot. And it's been proposed by parties other than just Google.
Or they could just use upnp like everyone else and enjoy a decent P2P connectivity rate without exposing your private IPs and making you fingerprintable.
More concerning, though, is that this stuff isn't triggering a permission dialog in Firefox.
www world really needs more www "browsers", particularly some more that do not implement javascript. Would it hurt to give users more choice and see what they choose?
Only my opinion but there is much one can do without all the .js
I certainly do not need Javascript to fetch some newspaper articles via HTTP.
I use dillo and netsurf for that. Both are quite fast, dillo is the faster one, netsurf's layout breaks less.
Dillo is freaking fast, once you try it you start to wonder where the web went all bloated. Of course its layout engine is quite dated, AFAIK no HTML5 support whatsoever and I think there are many layout bugs too. I use it to load up huge static html pages, they just kill Firefox or Chromium on my netbook. It's certainly nicer than lynx, sometimes you want to look at images too.
But "modern", Javascript-enabled web browsers are generally not my friends. I am rather circumspect in when and how I use them.
If I need to use a modern web browser on the open web it is generally because I _need_ Javascript. Bank, etc.
Most of the time I can get what I'm after without using a web browser, and when I need to browse HTML I can do it with browser that has no Javascript engine linked in.
It all depends on what the user is trying to do. And not all users are the same.
For retrieving content I find I do not need a web browser.
For reading HTML I find I do not need a Javascript-enabled browser.
Looking at photos is a different task. When I used to use X11, there were a few good options for viewing large number of photos quickly.
Watching video is a different task. For this I prefer a dedicated application. Interestingly enough, the player I use on the iPad has a built-in FTP server, HTTP server... and a web browser. Quite useful.
Try again. tnftp, tcpclient and nc are my friends. And, increasingly, q's builtin TCP client (alas, closed source).
There was a short time long ago when I used wget. That period did not last very long.
curl is overloaded with "features" I will never use.
My idea of a good TCP client is a small, relatively simple program with few options that compiles quickly and easily.
FreeBSD's fetch utility is another one that comes to mind.
Perhaps counterintuitively, I feel I get more "control" from the simpler TCP clients with fewer options (that I complile myself) than I ever did from the more popular programs with too many options and unneeded libraries linked in by default.
But that's just my opinion, nothing more. I would not "recommend" the programs I use to anyone. It is just my personal preference to use them.
In reality we are not very different. My toolset of choice would be hget and htmlfmt in plan9 which, when combined, just show the plain text versions of pages, or my own shell scripts [1]
You would have fitted into the plan9 user community in the early 2000s and could still perhaps enjoy it today.
A small subset of us used the name "the Tim Berners-Lee kicking club", in reference to how one man killed the greatest tool ever created by adding a worse one on the top.
The only possible reason I can fathom that this would be useful would be for tracking unique users behind a NAT (i.e. corporate or educational) who block all cookies. Seems like a pretty niche edge case in the U.S., but I'd imagine this could be useful in, say, the EU where cookies are opt-in by law?
"The use of electronic communications networks to store information or to gain access to information stored in the terminal equipment of a subscriber or user is only allowed on condition that the subscriber or user concerned is provided with clear and comprehensive information in accordance with Directive 95/46/EC, inter alia about the purposes of the processing, and is offered the right to refuse such processing by the data controller."
So acquiring my internal IP address without consent for reasons other than need for establishing a webrtc connection that the user has asked for is against the law.
> "stored in the terminal equipment of a subscriber or user"
This seems like a very odd way of phrasing the law. The default user-agent string, for instance, is stored on the terminal equipment of the user, albeit in read-only memory. It can be used to distinguish one user from another. Therefore, could one argue that any site that includes the user agent in their logs would be violating this law?
And what if the user is not behind a NAT? In that case, the user's external IP address is the one their terminal equipment places in the TCP header... which would mean that it is necessarily stored in said terminal equipment. Did the user give up the right to the privacy of the information by connecting to the website in the first place? Must there be a right-to-refuse all the way down?
Or for subscription enforcement. Our local newspaper has a paywall, but I always read it on an iPad with private browsing. That gets me unlimited free access. I'm utterly amazed it's worked as long as it has.
It might be intentional. The so called leaky paywall. (It's also kinda hard to defeat assuming you want new visitors to be able to read a few articles without a big hassle)
Probably part of their marketing fingerprinting. Lets say you have a big company that only has a specific set of public IPs and you centrally manage browser updates, add-ons, and extensions. Previously any user from that network might show up as the same user in the NYT's marketing data. Now they have an extra piece of data to help differentiate them.
The issue isn't that the other party knows your IP, it's that this is an unexpected connection for no other purpose than to obtain your public IP, in addition to your LAN IP.
There is not even a connection. During the RTCPeerConnection's "ICE Gathering" process local IPs are discovered and, if STUN/TURN servers are configured within the RTCPeerConnection, STUN requests are sent to those servers (which help retrieving the public IP of the computer/router). But you don't need even to send a single packet in order to get local IPs (private ones, VPN ones, etc).
Here's another White Hat use case for local IP addresses.
You can use it to unobtrusively monitor license compliance for a SaaS biz. You charge each user. A user is constantly logging on from multiple browsers during the day (e.g. IE and Chrome). With local IP knowledge you can determine whether or not this is being done from the same machine (still abiding by license terms), or from multiple machines (most likely sharing with a colleague and breaking license terms).
Before this webRTC hack the only other way to do this that I am aware of, is via the dreaded Flash cookie.
I hope that doesn't catch on. I have a laptop, two desktops and a phone that I use depending on where I happen to be sitting. They are all me, though. Even desktop software like Adobe Creative Suite seems to acknowledge that people use more than one device these days.
This will raise a bunch of false positive, ruining the experience for legitimate users. I think you're better off focusing on increasing revenues by growing your user base instead of alienating existing ones.
That's true, so you have to manage those false positives with other data points.
A. How often do we see this user using multiple machines on the same day?
B. Is access being made from two different machines at the same time (very high indicator of license sharing)
At the end of the day no matter how much data you add to the equation, you are still dealing in probabilities. So as a business you must be careful about when and who you accuse of license violations.
{kind=link}
{kind=link}
"Dan Kaminsky here, my apologies for kicking up a ruckus. This is part of a bot detection framework I've built at White Ops; we basically are able to detect browser automation using resources exposed in JavaScript. Nothing dangerous to users -- or we'd go file bugs on it, which we do from time to time -- but it does provide useful data regarding post-exploitation behavior. Happy to jump on a call with anyone concerned or worried; I'm over at dan@whiteops.com."
[1] http://www.whiteops.com/company [2] https://isc.sans.edu/forums/STUN+traffic/745/2