My first thought: great - we can retire our in-house multi-part uploader (EvaporateJS) [0] and use AWS's. But digging into the API, it seems like most of the real work of multipart uploading (managing part failures) is not done by the SDK [1], so we'll stick with EvaporateJS. It's working pretty well for us. We've seen 22GB uploads go through (direct from browser to S3). The main issue that we know of [2] should be fairly easy to fix if anyone wants to contribute!
We had similar hopes, but for now we will continue to use our in-house multi part uploader. We have to sign every multi-part request server side, using an auth scheme that depends on the key and the user.
I'm not sure if it would be an improvement or not to give each of our users an IAM account that correlates to specific bucket acl which is based on user namespaces. It would lighten the load on our servers (don't need to sign each request) but now each user needs resources in IAM to be managed.
Thanks for the link to EvaporateJS. The recent price changes at Ink Filepicker make it untenable for our small needs and this looks like a great alternative.
The SDK handles retries on failed requests. There is a little bit of extra legwork to actually do the slicing of a Blob, but you should be able to call createMultipartUpload(), uploadPart() x N, followed by completeMultipartUpload(). The SDK will make sure that each individual part gets retried on failures. That said, it would be nice to have a helper for that process.
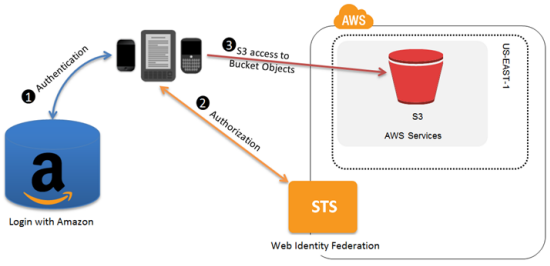
In the flow picture at the bottom, the STS looks like a server to me. What I'm saying is the auth flow still seems to require a server to act as an indirection to the real auth server. But if Amazon provide that part for us, great.
It's not just Amazon providing this-- there is Login With Amazon, but there is also Facebook and Google that act as identity providers. Unless I'm mistaken, this is how Google's storage APIs work too, by using OAuth/OpenID to get an access token that can then be exchanged for keys.
To me, one owns a domain, and ownership and trust in that domain is a source of authority. That authority will authenticate users, provide them with a set of credentials, and those credentials can then be used to write or store data. All that this method does is allow for the rest of the logic to be anywhere... client-side or server-side.
Because if you look at how Google Drive and Dropbox do it, they enable you to run fully client side and use their storage. I can serve the whole thing statically, it's far simpler architecturally and saves a ton of CPU and bandwidth costs.
From what I'm reading, you can't do this auth fully client-side.
How does this generate security credentials for a user client side? It mentions Identity Federation[1], but it looks like that links with Google , Facebook, or Login with Amazon. Is there a way to to authenticate a user without a 3rd-party login service?
An application can provide a server-side component that vends credentials to clients. Mobile applications on AWS used to do this with the Token Vending Machine[1]. I say used to because web identity federation is a much more powerful and lightweight way to vend credentials. Instead of hosting your own auth backend, you can offload that to another identity provider like Login With Amazon, Google, or Facebook.
Certainly, though, if you want total control of your own auth, you can still use the TVM or something like it to get credentials into your application. It does require that you are running a backend server though, which the client-side JS is meant to remove.
I really apologize for a very cursory read on my part, but I'm guessing it is in the same manner that CORS uploads to S3 is handled: http://aws.amazon.com/articles/1434/
If your application is only using S3 to upload objects, the full SDK would probably be overkill. Using pre-signed forms is sufficient there. However, if you want to use other services like DynamoDB, SQS, or SNS, pre-signed URLs will not work. Also note that in order to generate a pre-signed URL you still need a backend service running to sign those URLs, something you can avoid with the client-side SDK.
Ah ok yeah that makes sense. Pre-generate a signed token and post it along with the form. I guess in that case you wouldn't even need the jS-SDK since you can just do a normal POST/PUT to the s3 bucket with those credentials. I guess I got excited only to realize nothing would change ;)
"Each request must be signed with your AWS credentials. ..
Our web identify federation feature to authenticate the users of your application. By incorporating WIF into your application, you can use a public identity provider (Facebook, Google, or Login with Amazon) to initiate the creation of a set of temporary security credentials."
http://media.amazonwebservices.com/blog/2013/iam_web_identit...
I rather disagree with getting your autherization tokens by the grace of Google and Facebook.
It seems simple enough to roll your own, perfect use case for App Engine actually:
(Gets temp S3keys)
User <--------------------------> Logins to your site (AppEngine)
ˇ
S3
I just wish Amazon offered better late rimiting options and intergration behind the scenes. The 'Each Request' phrasing can be misleading, you don't need to sign each request, you can give the client side app a token that will last for an hour or a week. (But its on you to refresh it when it expires and keep track of how its being used so there's no abuse)
Well lets say I have a TokenFactory running somewhere (my servers, AppEngine, whatever) and my app is called Shminstegram - when my users login and get a token that's good for say 1 hour, I probably don't want them uploading 10,000 photos in that time period. That's probably a bot.
Now I could manage this myself with a background task that crunches S3 logs at its own pace and when it notices abuse it reports it to my TokenFactory so next time that user asks for a fresh token they get denied... but it would be great if S3 was a tad smarter about such things on its own. :)
Does that sort of make sense? In other words a token should have finer grained permissions than just time. Maybe... "Accept this token for the next 24 hour, or 200 POSTs, which ever comes first, and no more than 20 POSTs in the last hour." That sort of thing.
You can limit objects by size with the existing ACL's already. But you can't specify how many objects overall a user may upload in some time frame, or their accumlated size.
So you can have a token for: upload as many objects as you want of size less than 1MB in the next 1 hour.
You can't have a token for: upload no more than 1000 objects of size less than 1MB, in the next 1 hour and cut them off after 200MB Total.
How do you do security when making calls to DynamoDB directly from the browser? Does that mean a user can do anything it wants with your DB by forging the JS?
EDIT: Ok, so it says in the post. Fine-Grained Access Control for Amazon DynamoDB. Good stuff.
{kind=link}
[0] https://github.com/TTLabs/EvaporateJS [1] http://docs.aws.amazon.com/AWSJavaScriptSDK/latest/frames.ht... [2] https://github.com/TTLabs/EvaporateJS/issues/6