Relational databases have a history of absorbing the advantages of other systems when they come along, particularly changes to the model (cf. object databases and XML databases). As the author shows, a similar thing will happen quite quickly for document models.
Architectural changes are slower, but you can also start to see this happening in postgres with features like unlogged tables (i.e. don't write to the recovery log for changes to this table) and transaction-controlled async commit (i.e. don't wait for this transaction to hit disk). More changes are in the works.
MongoDB will have a chance to have an impact, and will be successful if they are able to keep innovating. If they just stand still or incrementally improve, they will be marginalized. Now that Mongo has center stage in the NoSQL movement, it will be interesting to see what they do next.
I'd phrase this differently. Once you implement Mongo in Postgres, what you have isn't a relational database.
What you are taking advantage of is the incredibly solid underlying infrastructure of Pg, which provides reliability, scalability, transactions, replication, etc.
But the data model itself is no longer relational from the application's perspective.
I do encourage any SQL user, who hasn't already tried MongoDB, to fire it up and try it themselves. Mongoid in Ruby is fairly fast to get started.
I've been using SQL since early 90s. For web apps and large collections I've started using MongoDB more recently. It's one of the most exciting technologies I've used in a long time.
It takes a while to stop thinking SQL, but once you pass that it's really very primitive (in a good way) - and frictionless for development. It really fits what I want to do with web apps in particular.
So far I've not needed to scale it, but I've less apprehension about that than I used to have about scaling SQL back in the day - the large denormalised tables I used to build from SQL for performance are now the default.
SQL still has a place and MongoDB is no replacement for complex models, but give it a try before buying that you can do it all with Postgres tweaks.
Experimenting with new technologies is encouraged, especially since cross-pollination of ideas happen this way.
However I would actually advise developers to stop and think if they really need MongoDB or the latest fad, because their current relational database, such as PostgreSQL, does a mighty fine job for most of their needs.
Why? Because I have never seen angry opinions about PostgreSQL losing people's data. Or about how the modeling tools and architecture exposed by PostgreSQL are insufficient for certain problems ... not until you're operating at Google's scale, and MongoDB won't save you there ;)
give it a try before buying that you can do it all
with Postgres tweaks
My main problem with most NoSQL solutions is that I have to tweak the problems I have to fit the solution, instead of the other way around. Technologies that can be tweaked simply rock.
> My main problem with most NoSQL solutions is that I have to tweak the problems I have to fit the solution, instead of the other way around. Technologies that can be tweaked simply rock.
Well, I would disagree. While it's great that sql databases let you do lots of joins, I would lose imagination of my query complexity very fast (also, you can't review all sql-queries stopping people from doing joins and "where tablename.status=active" in every joined table). While MongoDB would restrict you from that, but gives you "documents". I'd say it's a lot of power of complexity-clarity (having no joins, but power-enough documents).
p.s.: and yes, I agree with you that developers are ok with postgres on most of cases. more of that, it's better to have transactions and other stuff until it's performance-urgent to disable it).
> However I would actually advise developers to stop and think if they really need MongoDB or the latest fad, because their current relational database, such as PostgreSQL, does a mighty fine job for most of their needs.
Every time I've had to use an ORM, it always became a headache sooner or later. It got to the point where I stopped even trying to perform an automatic mapping; I reverted back to using explicit SQL in my code and avoided the "abstraction" altogether.
With a document store like MongoDB, though, the mapping between object and document is almost seamless. It's actually really quite comfortable.
Can you give an example? I don't generally have these problems and would like to see if it's my way of thinking or if you're working with vastly different data to me.
Since the relational model is very set-oriented, it has always had a particularly hard time dealing with ordered lists. But that's really a minor thing, and is actually something an ORM can do well to abstract.
My real headache with ORM has always been to get it to perform efficiently. For example, say I want to iterate through the GPA's of all the students. To do so, the ORM usually pulls in the full object model for each student - multiplying the cost of the desired operation by 10x or 100x. Now, each ORM tool usually has some tweaky knob or special declaration you can use to have it limit the fields queried, but by the time you figure out the right incantation you may as well have written the SQL yourself.
But wait! The ORM tool often saves you from this sort of overhead by caching the object model in memory. Alas, therein lies my biggest headache with ORM. "There are only two hard things in Computer Science: cache invalidation, naming things, and off-by-one errors."
I've used ORM tools such as the one in Django, Active::Record and DBIx::Class.
I do not have the issues you mentioned ... I always remember the API calls I need to make and performance has not been an issue (granted, I'm fairly familiar with all issues that can come up, so I know when or where to optimize in general).
the ORM usually pulls in the full object model for each student
Here's how to do it in Django (and note this is off the top of my head):
for row in Student.objects.values_list("gpa"):
print row[0]
You're really talking about shitty ORMs or APIs you haven't had the patience to become familiar with.
by the time you figure out the right
incantation you may as well have written the
SQL yourself
That's not true. On complex filtering, you often want to add or subtract filters based on certain conditions. With plain SQL you end up doing really ugly string concatenations, whereas with a good ORM the queries are composable.
I should acknowledge that these issues apply just as much to a document store as to a relational database. However, you tend to interact with a document store differently, since there is no need for a mapping abstraction. You often just use the database primitives provided, instead of going through a 3rd party. It's akin to manually using SQL in your code, where the database naturally knows what you're asking for.
I guess if only I "woke up" I would realise that PostgreSQL is the answer to all my problems. Guess what. PostgreSQL is just another SQL database. It's definitely one of the best ones but it still stuffers from all the same issues, limitations and frustrations. Many of which stem not from the database itself but from the relational modelling and tools to support it.
I use Java + MongoDB and life is significantly better now that I don't have to worry about the domain model so much. I can have lists, maps etc and can add classes or make changes seamlessly. It's worth the tradeoffs for me.
I wouldn't call it just another SQL database. The extensible type system is actually really cool and you can do a lot with it, and the same goes for Listen/Notify. It's actually an application development platform in a box.
But I guess here's the flip side. PostgreSQL is another relational database and and that means fundamentally it operates on sets of tuples. For anything where set operations are helpful, the relational model brings something that no other models bring to the table. I doubt I will ever see a viable ERP suite written on a NoSQL system.
OTOH, there are plenty of areas where set operations are not that big of a deal. In this area, a networked, mostly reliable, multi-master replicated store of application state data is a really really cool thing. For example, imagine MongoDB as a backplane for an LDAP forest, replacing local BDB storage for something like OpenLDAP. The source data may be in a more mature data store somewhere and fed into MongoDB so if it gets lost it isn't the end of the world (just possibly some temporary business hicups). Same with, say, Root DNS root servers.
Ahem, lists and maps seem a very easy thing to do in SQL. Where you get to the limits of the relational model is when three structure diversity is out of your hands, for instance a big bunch of parametrized messages.
I haven't done this in a few years, but Datamapper had the nice capability to map a singe model classes to multiple backends (e.g., use PostgreSQL for some attributes, MongoDB for others).
PostgreSQL and MongoDB cover most of my data store requirements and are a pleasure to use.
I use datamapper pretty extensively to join mysql tables with mongodb collections, but I've always used associations between several models to do this. Do you have any links talking about this capability?
> SQL still has a place and MongoDB is no replacement
Let's flip this: NoSQL is finding it's place in the database ecosystem.
SQL is the name of a database query language, NoSQL is a term that identifies a set of new, ostensibly non-relational, data storage engines that so implement an SQL parser despite SQL being the Standard Query Language, with twenty years of history behind it.
My opinion - They decided to call it NoSQL, not because SQL requires a relation database, but because writing a smart query optimizer is hard task. Much harder than writing the storage engine itself.
I'd much rather access data from Mongo, Riak, Redis, and Couch using the SELECT, INSERT, UPDATE and DELETE statements that I have known since 1988, instead of having to learn four new database APIs.
"I'd much rather access data from Mongo, Riak, Redis, and Couch using the SELECT, INSERT, UPDATE and DELETE statements that I have known since 1988, instead of having to learn four new database APIs."
Doesn't work because those are set operations which are meaningless outside the relational world. If you want to use set operations, use a relational database.
I'm going to disagree. A partial implementation of SQL would go a long way to clearing the stigma of "You old RDBMS users don't know what you're doing" that NoSQL engenders.
They are database operations, originally implemented against database management systems that attempt to map relational algebra (set operations) onto data stores. There is nothing in the SQL grammar that prevents its implementation outside RDBMS.
> "Doesn't work because those are set operations which are meaningless outside the relational world. If you want to use set operations, use a relational database."
I don't want to do set operations, I want to retrieve data.
SELECT * FROM user_collection WHERE city = 'Bronx'
expresses a desire for data, not a desire to perform a bunch of set operations, and should be functionality that is provided but the database vendor since we've had SQL since the 1980s and "everybody" knows SQL.
It is telling that they explain API examples in terms of SQL SELECT statements. I infer that if they wanted to do the work they could provide a SQL processor, and extrapolate to every other API-only datastore.
This is (almost) exactly what Goatfish[1] does, except it uses SQLite, and can create SQL indexes on any arbitrary field. I needed a schemaless, embeddable store, so I decided to go with that, since Postgres already has the hstore. It's still very simple and preliminary, but it works, and it's very useful for prototyping.
I'd like to develop it some more, if people found it useful and started using it.
If you just need a simple key/value, a good way to go is HSTORE in PostgreSQL. It allows only string key/values, and not complex structures. Use the JSON datatype if you need lists, nested objects etc.
I wonder if postgres will adopt BSON instead of JSON and implement all the querying -- that would be so much better.
p.s.: guys who disagree -- why would you do that? I mean, BSON lets you quickly skip (embedded) documents you're not interested in, since it stores their size. Also it has type info and some additional types. So it's just "better JSON" for storing and navigating, and if postgres wants to have querying in JSON, they will either take BSON or invent the wheel for something similar.
It is interesting, but what I really need in the JSON functionality of PG is some internal representation that will allow fast and efficient exploration of the JSON blob within the query. i.e. being able to refer to a single attribute within the select/where/groupby clauses without having to pay the toll of serde every time.
Wouldn't that kind of defeat the purpose of using a document database in the first place? Being able to throw unstructured data into the system, and then being able to query on that data once the space is better understood is where the document databases really shine.
If you are able to start with rigid structure, you, in many cases, could have just used a relational database to begin with.
In my (limited) experience with Mongo, its just not like that.
You can't just (quickly) query any key in the document - you have to define indexes anyway or you'll be doing the equivalent of a table scan or Map/Reduce.
Document databases shine when you're just not doing that kind of query anyway, and you've got a ton of data to store. If you need to do e.g., fulltext and/or geospatial search you should probably use a search server anyway (I like Sphinx), and then just lookup by PK in whatever datastore you're using.
Its been mentioned elsewhere on this thread, but I'm also quite fond of the old FriendFeed method: serialize your arbitrary data into a (MySQL) BLOB, and then run a background process to build "indexes" (really tables) when you find out you need them.
Its ridiculously simple to start doing that, and there's no new tech to learn.
Defining 'right', and being able to predict 'right' for future iterations/versions of an app's life is where that mantra seems to fall down.
I'm not a huge nosql fan right now, given that I sometimes need document-style schemaless data storage, but I always (eventually) need adhoc reporting and relational querying capabilities on projects. With that (fore)knowledge, I may as well always choose a relational db.
Well, what I need is expressive and flexible querying over document data that doesn't have a rigid schema. There are several document stores that provide filtering and retrieval matching that, but they all have various limitations when it comes to aggregation.
Serialized is already denormalized, you're talking about a kind of double-denormalization where you introduce metadata as a guide for the serialized-data queries. Spaghetti.
exactly. calling the find_in_obj() function can get fairly expensive, especially given the need to execute JSON.parse() for every call.
there is definitely a lot of room for improvement in the postgres native JSON toolkit. i am hoping that building this exposes more of those issues and helps move it forward.
I haven't tried it, but I think you would be able to use a PostgreSQL functional index (i.e. indexing the result of a function call to extract a particular bit of data from the JSON.)
I was just coming here to say exactly this. You could also use a partial index (that is, an index with a WHERE clause; so, "WHERE json_field LIKE '%foo.bar = baz%'" or whatever).
Immutability is perfectly appropriate for that use-case, though. Creating an index via a function that may return different outputs when provided the same input is always going to lose.
But the same is true for MongoDB. If you're querying an attribute of a document that isn't indexed, Mongo has to scan all of the Documents in the collection for it. The solution to this is to have additional indexes on any attributes you want to be able to query by. This holds true both in Mongo and this Postgres implementation.
This is the right way to think about building a "NoSQL" datastore.
I think that schemaless, eventually-consistent data stores have a place and are useful. I just think that most of the current efforts are throwing away years of investment in SQL datastores. Rather than thinking of NoSQL as a brand-new paradigm shift that requires a ground-up reimplementation, we need to think of it as layer of abstraction on top of MySQL and memcache (or your preferred setup). Re-implementing all of the work that has gone into these projects is a bad idea and is contrary to The Unix Way.
Thinking of SQL databases as a storage engine rather than the kitchen sink is the key to building a scalable system.
Should be pretty trivial for him to shard collections across multiple databases with the same level of intelligence as MongoDB's automated sharding simply using the primary key, since MongoDB doesn't join.
Not sure how sharding is the point of MongoDB, though - in most of the universe, sharding is a database architecture/schema-level thing, not a database-server level thing, and for good reason - it's pretty darn hard for a database server to shard effectively without some knowledge of the app layer (and which keys are likely to become hot).
Personally, if I really wanted a flexible-schema "document based" database, I'd have implemented this using the FriendFeed K/V + Index model ( http://backchannel.org/blog/friendfeed-schemaless-mysql ) plus Postgres's HStore functionality, storing K/V per document in an HStore rather than in one giant K/V table like FriendFeed. That way I wouldn't need to use V8 and JSON parsing to run queries, and the mythic MongoDB-style "sharding" would be just as easy (just distribute the document -> hstore table across shards keyed on ID again).
I disagree that sharding can ever be a trivial problem if you're going to try to tackle moving data between shards while staying online. I'm not saying it's impossible, just that it's not trivial.
MongoDB's relatively simple approach involves continuing to use the old shard as an authoritative source (and committing updates to it) while shipping data in the background, then pushing the additional changes across and marking the new shard as "master."
Such an approach wouldn't be horribly difficult to implement in SQL using a copy table and write triggers - almost identically to how SoundCloud's Large Hadron Migrator allows writes to occur over a MySQL InnoDB table that's locked for migration (but even simpler because the table schema can't conflict afterwords).
The entire problem is admittedly nontrivial, since if the application happens to be writing data to the shard under migration too quickly (or the shard being migrated to dies), the server can end up in a situation where the new shard is never able to catch up and become a master. However, the easy solution (give up and retry later) is Good Enough for most situations (and is pretty much how MongoDB works).
"Unless he's planning to build sharding on postgres too, I think he's missing the point."
NoSQL seems to have three general claims (I'm not saying whether these are correct or not): (1) ease of administration in some cases; (2) different data model; (3) better performance or availability in some situations.
The author is clearly addressing the second, and you are clearly talking about the third.
You have a good point. I must admit that after many years of using and loving PostgreSQL I have never had to scale it out: that is outside of my experiences.
On the other hand, old fashion MongoDB master slave configurations and now replica sets have been easy for me to set up when on just a few occasions I had to use a scaled out MongoDB setup.
I don't know if it's the _most_ important feature, but I wouldn't build a serious site on top of anything that didn't have some sort of built-in sharding story.
With postgres you have to roll your own. If you want to bridge the gap from postgres to mongo, I think that's where you have to start.
Postgres-XC is also in beta. Basically it's sharded PostgreSQL with full RI enforcement between shards, and seamless query integration. I assume they are working off the 9.2 codebase (hence the beta being the same time as Pg 9.2) but maybe it's only 9.1 (i.e. no JSON).
Postgres-XC is probably the most exciting PostgreSQL-related project out there. It promises full write-extensibility across the cluster without sacrificing consistency.
Fair, my statement was overly broad. Sites that are read-only or store blob data in something like S3 can often avoid sharding for quite a while and rely on machines to just get bigger over time.
That said, if your site grows in some way you didn't originally anticipate and you get to a point where you need to shard, but can only do so by changing data stores, then it's sad.
> That said, if your site grows in some way you didn't originally anticipate and you get to a point where you need to shard, but can only do so by changing data stores, then it's sad.
I don't agree. Almost every site that grows in ways that weren't anticipated (or at a scale that wasn't anticipated) will have to make technical changes. If you don't need to make any changes it's almost certainly the case that you originally over-engineered. If you're optimizing for cases that you don't anticipate, I don't know what to call it other than over-engineering. Facebook started simple and only made Cassandra when they needed to, Google didn't have BigTable when they started, etc etc.
" Sites that are read-only or store blob data in something like S3 can often avoid sharding"
Still too broad. Sorry, this is a pet peeve of mine, where tech people assume that everyone else has the same issues as them. For example, I worked on an ecommerce site that made over a mil a year. They had less than 10k products, and will never need sharding. They are not read-only, they have people updating their products on a daily basis through the site.
My definition of seriousness includes some relatively large scale. Your definition of seriousness appears to mean any site that is important to the person or business running it. Is that a fair assessment?
I think your definition is better, and I should've said "a potentially-large site" or something like that.
Yes, this. Thanks for listening. It's a pet peeve of mine because most people work on serious sites, and a minority of them have large scale data, but people often imply that everyone needs to solve massive scaling problems even if they will never have them.
Every large site on the internet has talked about strategies around sharding. At some point you are surely going to hit the physical limitations of one database on one server.
He said "serious site". He did not say "large site". For example, techcrunch is most certainly a serious site. It is NOT large scale and in need of sharding.
"That said, if your site grows in some way you didn't originally anticipate and you get to a point where you need to shard, but can only do so by changing data stores, then it's sad."
I think you're being too absolute. For instance, Instagram used sharding in postgres, and they didn't have to throw anything away or dedicate any huge engineering team to solve it.
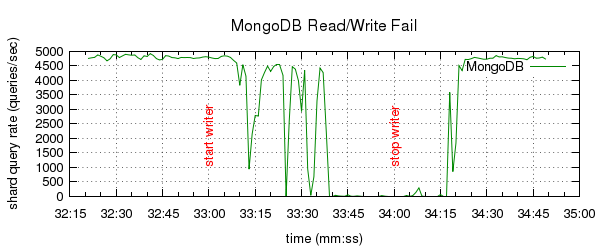
The sharding impl in MongoDB still[1] crumbles pitifully[2] under load. Regardless of sharding MongoDB still halts the world[3] under write-load.
Their map/reduce impl is a joke[4][5].
If you had done the slightest research you'd know that every single aspect that you need to scale out Mongo is either broken by design or so immature that you can't rely on it.
MongoDB may be fine as long as your working set fits into RAM on a single server. If you plan to go beyond that then you'd better start with a more stable foundation - or brace yourself for some serious pain.
[1] looks like an example where the data didn't fit in RAM. Mongo works best when data fits in RAM or if you use SSD's. Yes, it's sub-optimal.
[2] is from a year and a half ago. It doesn't belong in a sentence that includes the word "still." I work at foursquare, btw. Those outages happened on my first and second days at the company. I wasn't so keen on mongo then either. We've gotten much better at administering it. Basically all our data is in mongo, and it has its flaws, but I'm still glad we use it.
[3] is also from a year and a half ago. Mongo 2.2 will have a per-database write lock, which is at least progress, even though it's obviously not enough. Since 2.0 (or 1.8?) it's also gotten better at yielding during long writes.
I have no experience with their mapreduce impl and can't speak to it.
[2] When you look at [1] you'll notice that these exact problems are still prevalent.
I'd in fact be curious how exactly did you work around the sharding issues at 4square?
Remember I replied to someone who claimed it takes "no engineering effort" to scale MongoDB. That's not only obviously false, but last time I tried the sharding was so brittle that recommending it as a scaling path would border on malice.
I ran a few rather simple tests for common scenarios; high write-load, flapping mongod, kill -9/rejoin, temporary network partition, deliberate memory starvation. MongoDB failed terribly in every single one of them. The behavior would range from the cluster becoming unresponsive (temporary or terminally), over data-corruption (collection disappears or inaccessible with error), silent data-corruption (inconsistent query-results), to severe cluster imbalance, to crashes (segfault, "shard version not ok" and a whole range of other messages).
I didn't try very hard, it was terribly easy to trigger pathological behavior.
My take-home was that I most certainly don't want to be around when a large MongoDB deployment fails in production.
As such I'm a little disconcerted every time the Mongo scalability myth is reinstated on HN, usually by people who haven't even tried it beyond a single instance on their laptop.
"I ran a few rather simple tests for common scenarios; high write-load, flapping mongod, kill -9/rejoin, temporary network partition, deliberate memory starvation. MongoDB failed terribly in every single one of them. "
What other databases did you go to the same lengths to make fail which handled them gracefully?
I don't think what I said was bullshit. So you wrote tests to make mongo fail, and you've seen cases where people run into problems with it. That still doesn't disprove my point. With postgres, you roll your own sharding. With mongo, you don't have to.
It seems you fall squarely into the bucket of 'people who haven't even tried' (and some other unfavorable buckets, but I'll leave that to your older self to judge).
Well that's just factually incorrect. MongoDB now has a per-database write lock and will have a per-collection write lock in the next version. So your halt under write-load statement is incorrect.
The map reduce implementation is quite new sure. But it is getting better and you can always link it up with Hadoop.
At the very least provide links that aren't nearly 2 years old.
MongoDB now has a per-database write lock and will have a per-collection write lock in the next version.
That doesn't help when you need to make a bulk-update on a busy collection. Busy collections have a tendency towards being in need for bulk updates occasionally.
At the very least provide links that aren't nearly 2 years old.
The first link is 1 month old.
The other links also still describe the state of the art. Feel free to correct them factually if that is not true.
I attended a talk by Instagram post-buyout. That's where I got the impression that sharding was not a huge obstacle for them (though it was significant). Keep in mind their entire data management team was 2 people I think.
My point was that sharding is not an absolute "have it or not". Some features require major engineering efforts to get anywhere at all, but sharding is not one of them.
But if you think the overall effort is less with MongoDB then go for it.
I would say most sites will do just fine without sharding. You can get very far by just scaling up with a more expensive database server and caching the most common read operations. Some of the largest websites in the world do not need to do more than this.
Hi, disclaimer - I work for ScaleBase, giving a true automated transparent sharding, so I live and breath sharding for 4 years now...
The main problem is user/session concurrency. On one machine - it kills at some (near) point. A DB is doing much more for every write then reads (look at my blog here: http://database-scalability.blogspot.com/2012/05/were-in-big...). The limit is here and now, even 100 heavy writing sessions will choke the MySQL (or any SQL DB...) on any hardware.
Catch 22: Scale-out to repl slaves with R/W splitting? This can lower read load on the master DB, but read load can be better lowered by caching. The problem is writes and small supporting transactional reads, and slaves won't help. Distributing data (sharding?) is the only way to distribute write intensive load, and it also helps reads by putting them on smaller chunks, and parallelizing them is a sweet sweet bonus :)
As I see around (hundreds of medium-large sites) - there's no other way...
And one final word about the cloud: "one DB machine" is limited to a rather limited non-powerful virtualized compute and I/O space... In the cloud limits are here and now! Cloud is all about elasticity and scale-out.
I'm not sure why you said "a single database server". No one said that. We're talking about sharding across databases, and the vast majority of sites don't need that.
Having a master/slave setup is more than a single server, but it's NOT the same as sharding.
> I don't know if it's the _most_ important feature, but I wouldn't build a serious site on top of anything that didn't have some sort of built-in sharding story.
You know people say this, but in practice I find that simple hash bucketing with a redundant pair works surprisingly well, particularly in the cloud. Yes it isn't fancy, but it is trivial to manage and debug, and you can do a lot of optimizations given such a clear cut set of partitioning rules.
Your problems have to get really big before a more sophisticated mechanism really pays off in terms of avoiding headaches, and often the more sophisticated mechanisms actually cause more headaches before you get there.
{kind=link}
Architectural changes are slower, but you can also start to see this happening in postgres with features like unlogged tables (i.e. don't write to the recovery log for changes to this table) and transaction-controlled async commit (i.e. don't wait for this transaction to hit disk). More changes are in the works.
MongoDB will have a chance to have an impact, and will be successful if they are able to keep innovating. If they just stand still or incrementally improve, they will be marginalized. Now that Mongo has center stage in the NoSQL movement, it will be interesting to see what they do next.