I've just started this video, but already have a question if anyone's familiar with GPT workings - I thought that these models chose the next word based on what's most likely. But if they choose based on "one of the likely" words, could (in general) that not lead to a situation where the list of predictions for the next word are much less likely? Running possibilities of "two words together", then, would be more beneficial if computationally possible (and so on for 3, 4 and n words). Does this exist?
(I realize that choosing the most likely word wouldn't necessarily solve the issue, but choosing the most likely phrase possibly might.)
Edit, post seeing the video and comments: it's beam search, along with temperature to control these things.
In practice, beam search doesn't seem to work well for generative models.
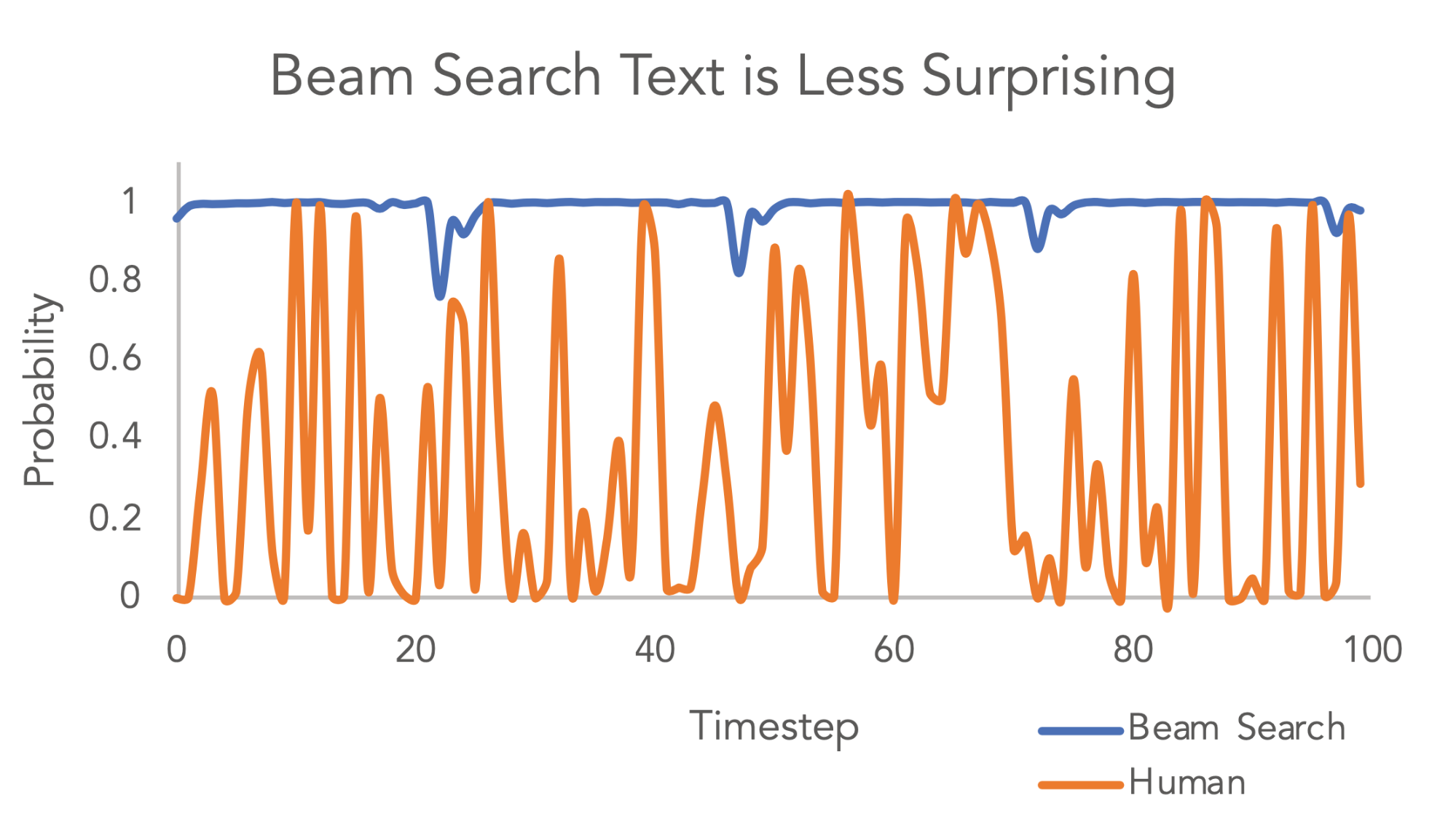
Temperature and top_k (two very similar parameters) were both introduced to account for the fact that human text is unpredictable stochastically for each sentence someone might say as such - as shown in this 2021 similar graph/reproduction of an older graph from the 2018/2019 HF documentation: https://lilianweng.github.io/posts/2021-01-02-controllable-t...
It could be that beam search with much longer length does turn out to be better or some merging of the techniques works well, but I don't think so. The query-key-value part of transformers is focused on a single total in many ways - in relation to the overall context. The architecture is not meant for longer forms as such - there is no default "two token" system. And with 50k-100k tokens in most GPT models, you would be looking at 50k*50k = A great deal more parameters and then issues with sparsity of data.
Just everything about GPT models (e.g. learned positional encodings/embeddings depending on the model iteration) is so focused on bringing the richness of a single token or single token index that the architecture is not designed for beam search like this one could say. Without considering the training complications.
The temperature setting is used to select how rare of a next token is possible. If set to 0 the. The top of the likely list is chosen, if set greater than 0 then some lower probability tokens may be chosen.
Not quite... temperature and token selection are two different things.
At the output of an LLM the raw next-token prediction values (logits) are passed through a softmax to convert them into probabilities, then these probabilities drive token selection according to the chosen selection scheme such as greedy selection (always choose highest probability token), or a sampling scheme such as top-k or top-p. Under top-k sampling a random token selection is made from one of the top k most probable tokens.
The softmax temperature setting preserves the relative order of output probabilities, but at higher temperatures gives a boost to outputs that would otherwise have been low probability such that the output probabilities are more balanced. The effect of this on token selection depends on the selection scheme being used.
If greedy selection was chosen, then temperature has no effect since it preserves the relative order of probabilities, and the highest probability token will always be chosen.
If a sampling selection scheme (top-k or top-p) was chosen, then increased temperature will have boosted the likelihood of sampling choosing an otherwise lower probability token. Note however, that even with the lowest temperature setting, sampling is always probabilistic, so there is no guarantee (or desire!) for the highest probability token to be selected.
Can this be potentially dangerous -- e.g. if a user types "The answer to the expression 2 + 2 is", isn't there a chance it chooses an output beyond the most likely one?
That assumes that the model is assigning vanishingly small weights to truly incorrect answers, which doesn't necessarily hold up in practice. So I think "Unless you screw something" is doing a lot of work there
I think a more correct explanation would be that increasing temperature doesn't necessarily increase the probability of a truly incorrect answer proportionately to the temperature increase (because the same correct answer could be represented by many different sequences of tokens), but if the model assigns a non-zero value to any incorrect output after applying softmax (which it most likely does), increasing the temperature does increase the probability of that incorrect output being returned.
I would guess that any mentioning of the Radiohead nearby would strongly influence answers, due to the famous "2 + 2 = 5" song.
And if I understand correctly, then there is a chance that some tokens that are very close to the "Radiohead" tokens could also influence the answer.
So maybe something like "It's a well-known fact in the smith community that 2 + 2 =" could realistically come up with a "5" as a next token.
Yes, although it's also possible that the most likely token is incorrect and perhaps the next 4 most likely tokens would lead to a correct answer.
For example if you ask a model what is 0^0, the highest probability output may be "1", which is incorrect. The next most probable outputs may be words like "although", "because", "Due to", "unfortunately", etc. as the model prepares to explain to the user that the value of the expression is undefined; because there are many more ways to express and explain the undefined answer than there are to express a naively incorrect answer, the correct answer is split across more tokens so that even if eg the softmax value of "1" is 0.1 and across "although"+"because"+"due to"+"unfortunately">0.3, at temperature of 0, "1" gets chosen. At slightly higher temperatures, sampling across all outputs would increase the probability of a correct answer.
So it's true that increasing the temperature increases the probability that the model outputs tokens other than the single-most-likely token, but that might be what you want. Temperature purely controls the distribution of tokens, not "answers".
I honestly had forgot that, if I ever knew it. But I think the point stands that in many contexts you'd rather have the nuances of this kind of thing explained to you - able to represented by many different sequences of tokens, each individually being low probability - instead of simply taking the single-highest probability token "1".
> Can this be potentially dangerous -- e.g. if a user types "The answer to the expression 2 + 2 is", isn't there a chance it chooses an output beyond the most likely one?
This is where the semi-ambiguity of the human languages helps a lot with.
There are multiple ways to answer with "4" that are acceptable, meaning that it just needs to be close enough to the desired outcome to work. This means that there isn't a single point that needs to be precisely aimed at, but a broader plot of space that's relatively easier to hit.
The hefty tolerances, redundancies, & general lossiness of the human language act as a metaphorical gravity well to drag LLMs to the most probable answer.
You really couldn't come up with an actual example of something that would be dangerous? I'd appreciate that, because I'm not seeing reason to believe that an "output beyond the most likely one" output would end up ever being dangerous, as in, harming someone or putting someone's life at risk.
There's no need for the snark there. I mean 'potential danger' as in the LLM outputting anything inconsistent with reality. That can be as simple as an arithmetic issue.
That depends on how many people are putting blind faith in terrible AI. If it's your doctor or your parole board, AI making a mistake could be horrible for you.
Yes, this is a fundamental weakness with LLMs. Unfortunately this is likely unsolvable because the search space is exponential. Techniques like beam search help, but can only introduce a constant scaling factor.
That said, LLM reach their current performance despite this limitation.
Thanks, that's exactly what I was looking for! Any idea if it's possible to use beam search on local models like mistral? It sounds like the choice of beam search vs say top-p or top-k should be in the software and not embedded, right?
I will warn you though that beam search is typically what you do NOT want. Beam search approximately optimizes for the "highest likely sequence at the token level." This is rarely what you need in practice with open-ended generations (e.g. a question-answering chat bot). In practice, you need "highest likely semantic sequence," which is much harder problem.
Of course, various approximations for semantic alignment are currently in the literature, but still a wide open problem.
Thats basically chunking or at least how it starts. I was impressed by the ability to add and subtract the individual word vector embeddings and get meaningful results. Chunking a larger block blends this whole process so you can do the same thing but in conseptual space the so take a baseline method like sentence embedding and that becomes your working block for comparison.
There’s some fancier stuff too like techniques that take into account where recent tokens were drawn from in the distribution and update either the top_p or the temperature so that sequences of tokens have a minimum unlikeliness. Beam search is less common with really large models because the computation is really expensive.
IMO the style, formatting, and animations in 3B1B videos is what Coursera courses should have been about in the first place.
Andrew Ng's course doesn't use video effectively at all: half of each class is Andrew talking to the camera, while the other half is him slowly writing things down with a mouse. There's a reason why a lot of people recommend watching at 1.5x speed.
Online classes are online classes. If they try to make copy in-person classes, like most Coursera courses do, they will keep all of the weaknesses of online classes without any of its strengths.
I personally preferred Andrej Karpathy's CS231n taught by him and his private videos about neural nets in general and transformers in particular. He has a youtube vid where he builds one from scratch in Python!
3BlueOneBrown videos are a great complement to Karpathy's lectures to aid in visualising what is going on.
IMO I think the 3Blue1Brown video is a good place to start to build intuitions about how things work generally if you're new, and Andrew Ng's courses will help you dig into more detail, experiment, and implement things to build on those intuitions.
If you liked that, Andrej karpathy has a few interesting videos on his channels explaining Neural Networks and their inner workings which are aimed at people who know how to program.
As a reasonably experienced programmer that has watched Andrej's videos the one thing I would recommend is that they not be used as a starting point to learn neural networks but as a reinforcement or enhancement method once you know the fundamentals.
I was ignorant enough to try and jump straight in to his videos and despite him recommending I watch his preceeding videos I incorrectly assumed I could figure it out as I went. There is verbiage in there that you simply must know to get the most out of it. After giving up, going away and filling in the gaps though some other learnings, I went back and his videos become (understandably) massively more valueable for me.
I would strongly recommend anyone else wanting to learn neural networks that they learn from my mistake.
For me 3brown1blue series: https://m.youtube.com/watch?v=aircAruvnKk was an excellent introduction that made Andrej's videos understandable. Then I did 3 first chapters of fastai book, but found it too high level, while I was interested in how things works under the hood.
Going through Andrej's makemore tutorials required quite a lot of time but it's definitely worth it. I used free tier of Google Colab until the last one.
Pausing the video a lot after he explains what he plans to do and trying to do it by myself was a very rewarding way to learn, with a lot of "aha" moments.
The next token is taken by sampling the logits in the final column after unembedding. But isn't that just the last token again? Or is the matrix resized to N+1 at some step?
{kind=link}
(I realize that choosing the most likely word wouldn't necessarily solve the issue, but choosing the most likely phrase possibly might.)
Edit, post seeing the video and comments: it's beam search, along with temperature to control these things.