We shipped a shader cache in the latest release of OBS and quickly had reports come in that the cached data was invalid. After investigating, the cache files were the correct size on disk but the contents were all zero. On a journaled file system this seems like it should be impossible, so the current guess is that some users have SSDs that are ignoring flushes and experience data corruption on crash / power loss.
I think this is typical behaviour with ext4 on Linux, if the application doesn't do fsync/fdatasync to flush the data to disk.
Depending on mount options, ext4fs does metadata journaling ensuring the FS itself is not borked, but not data journaling which would safeguard the file contents in event of unclean shutdown with pending writes in the caches.
The same phenomenon is at play when people complain that their log files contain NUL bytes after a crash. The file system metadata has been updated for the size of the file to fit the appended write, but the data itself was not written out yet.
The current default is data=ordered, which should prevent this problem if the hardware doesn't lie. The data doesn't go in the journal, but it has to be written before the journal is committed.
There was a point where ext3 defaulted to data=writeback, which can definitely give you files full of null bytes.
And data=journal exists but is overkill for this situation.
For more context, that's a comment from one of the ext4 main authors, Ted Ts'o. the other subsequent comment from him spells out the case more but sadly no spelled out NUL byte origin story I spotted from skimming.
The original report [0] shows the corruption due to NUL bytes at the end of the file (see the hexdump).
This comment [1] from Ted Ts'o details the exact chain of events leading to it.
I do not know how zfs will overcome hardware lying. If its going to fetch data that is in the drives cache, how will it overcome the persistence problem ?
It will at the very least notice that the read data does not match the stored checksum and not return the garbage data to the application. In redundant (raidz) setups it will then read the data from another disk, and update the faulty disk. In a non-redundant setup (or if enough disks are corrupted) it will signal an IO error.
An error is preferred to silently returning garbage data!
The "zeroed-out file" problem is not about firmware lying though, it is about applications using fsync() wrongly or not at all. Look up the O_PONIES controversy.
Sure, due to their COW nature zfs and btrfs provide better behavior despite broken applications. But you can't solve persistence in the face of lying firmware.
Even thought zfs has some enhancements to not corrupt itself on such drives, if you run for example a database on top, all guarantees around commit go out the window.
"Renaming a file should always happen-after pending writes to that file" is not a big pony. I think it's a reasonable request even in the absence of fsync.
Well, for one rename() is not always meant to be durable. It can also be used for IPC, for example some mail servers use it to move mails between queues. Flushing before every rename is unexpected in that situation.
Fun fact: rename() is atomic with respect to running applications per POSIX, that the on-disk rename is also atomic is only incidental.
I'm not suggesting flushing for rename. If a file write and a rename happen shortly before power loss, and neither goes through, that's fine.
With this rule, three outcomes are acceptable: both occur, or neither occur, or just the file write happens. The unacceptable outcome is that just the rename happens.
("file write" here could mean a single write, or an open-write-close sequence, it doesn't particularly matter and I don't want to dig through old discussions in too much detail)
As an aside, can you still get the bad checksum file contents with zfs? Eg if it's a big database with its own checksums you might want to run a db level recovery on it.
Actual file data ends up in the same transaction group (txg) as metadata if both are changed within the same txg commit (either flushed explicitly, due to recordsize/buffer limit being reached, or txg commit timeout - 5 seconds by default), so if there is a write barrier violation caused by hardware lies followed by an untimely loss of power, the checksums for the txg updates won't match and they get rolled-back until the last valid one when importing the pool - which doesn't end up zero'ing out extents of a file (like in xfs) or ending up with a zero file size (like on ext3/ext4).
At least on linux you can use io_uring to make fsync asynchronous. And you can initiate some preparatory flushing with sync_file_range and only do the final commit with fsync to cut down the latency.
My only n=1 observation is that null values in logs occur on nvme, ssd and spinning rust. All ext4 with defaults. I do have the idea it occurs more on nvme drives though. But maybe my systems settings are just booked.
I don't think that's how it works: Flushing metadata before data would be a security concern (consider e.g. the metadata change of increasing a file's length due to an append before the data change itself), so file systems usually only ever do the opposite, which is safe.
Getting back zeroes after a metadata sync (which must follow a data sync) would accordingly be an indication of something weird having happened at the disk level: We'd expect to either see no data at all, or correct data, but not zeroes or any other file's or previously written stale data.
The file isn't stored contiguously on disk, so that would depend on the implementation of the filesystem. Perhaps the size of the file can be changed, without extents necessarily being allocated to cover the new size?
I seem to vaguely recall an issue like that, for ext4 in particular. Of course it's possible in general for any filesystem that supports holes, but I don't think we can necessarily assume that the data is always written, and all the pointers to it also written, before the file-size gets updated.
I think there could semi-reasonably be case for the zero bytes appearing if the fs knows there should be something written there, and the block is has been allocated, but no write yet. Then it's not compromising confidentiality to zero the allocated block when recovering the journal when the disk is mounted. But the zero byte origin doesn't seem to be spelled out anywhere so this is just off the cuff reasoning.
The file's size could have been set by the application before copying data to it. This will result in a file which reads all zeroes.
Or if it were a hardware ordering fault, remember that SSD TRIM is typically used by modern filesystems to reclaim unused space. TRIMmed blocks read as zero.
> The file's size could have been set by the application before copying data to it. This will result in a file which reads all zeroes.
Hm, is that a common approach? I thought applications mostly use fallocate(2) for that if it's for performance reasons, which does not change the nominal file size.
Actually allocating zeroes sounds like it could be quite inefficient and confusing, but then again, fallocate is not portable POSIX.
I had this exact experience with my workstation SSD (NTFS) after a short power loss while NPM was running. After I turned the computer back on, several files (package.json, package-lock.json and many others inside node_modules) had the correct size on disk but were filled with zeros.
I think the last time I had corrupted files after a power loss was in a FAT32 disk on Win98, but you'd usually get garbage data, not all zeros.
> but you'd usually get garbage data, not all zeros.
You are less likely to get garbage with an SSD in combination with a modern filesystem because of TRIM. Even if the SSD has not (yet) wiped the data, it knows that a block that is marked as unused can be retuned as a block of 0s without needing to check what is currently stored for that block.
Traditional drives had no such facility to have blocks marked as unused from their PoV, so they always performed the read and returned what they found which was most likely junk (old data from deleted files that would make sense in another context) though could also be a block of zeros (because that block hadn't been used since the drive had a full format or someone zeroed free-space).
They may be pointing to unallocated space which on a SSD running TRIM would return all zeros. NTFS is an extremely resilient yet boring filesystem, I cannot remember the last time I had to run chkdsk even after an improper shutdown.
As somebody who worked as a PC technician for a while until very recently, I've run chkdsk and had to repair errors on NTFS filesystems very, very, very often. It's almost an everyday thing. Anecdotal evidence is less than useful here.
So anecdotal evidence is not useful, as proven by your anecdotal evidence? :)
FWIW I've found NTFS and ext3/4 to be of similar reliability over the years, in general use and in the face of improper shutdown. Metadata journaling does a lot to preserve the filesystem in such circumstances. Most of the few significant problems I've had have been due to hardware issues, which few filesystems on their own will help you with.
It is worth noting that when you run tools like chkdsk or fsck, some of the issues reported and fixed are not data damaging, or structurally dangerous, or at least not immediately so. For instance free areas marked in such a way that makes them look used to the allocation algorithms.
There's a difference between your personal experience and my experience in a professional role handling multiple customer devices every day.
However, I'm also not making a statement about NTFS's reliability vs ext3/ext4. In the years that I worked in that position, I maybe dealt with Linux systems 3 times.
Reminder of the original statement:
> NTFS is an extremely resilient yet boring filesystem, I cannot remember the last time I had to run chkdsk even after an improper shutdown.
I never said anything about catastrophic failure of an NTFS filesystem. I have experienced that, but it was comparatively rare (still happened though). I have, however, have had to run chkdsk fairly often to correct errors. Sometimes user data was affected to some degree, but it was often a matter of system stability and getting Windows back to running without issues.
I still find that NTFS is reasonably resilient and have no qualms with it. I just want to push back against the idea that nothing ever goes wrong with NTFS, which was implied by your statement that you can't remember the last time you used chkdsk.
> not making a statement about NTFS's reliability vs ext3/ext4
I should have been a bit clearer there: I only mentioned those specific filesystems because those are the ones I have a lot of experience with, rather than intending to bang the drum for them (or one in favour of the other). I expect other much-tested journaled filesystems could be substituted into the same sentences.
Journaling filesystems (including NTFS, and ext3/ext4 using default mount options) typically only track file structure metadata in the journal, so that is WAI - the filesystem structure was not corrupted, but all bets are off when it comes to the contents of the files.
I lost Audacity projects due to BSODs on a Surface Book several times in ~2019: the *_data/**.au files were intact, each containing just a few seconds of audio; but the .aup XML file that maps them and contains whatever else makes up the project was all zeroed. My memory’s fuzzy, but I think it was something like exit sometimes triggering the BSOD, and save-on-exit corrupting consistently if it BSODed, and so the workaround was to remember to save first, and then if it BSODs you’re OK.
You mean on complete system crash, right? Your application crashing shouldn't lead to files being fulls of zeroes as long as you've already written everything out.
So is it the mods who are editing titles of articles to be more sensational and clickbait-y? Because this happens all the damn time, flagging does nothing, etc.
In many cases yes. I don't know if it's an automated or manual process (it seems to happen less when the US is asleep, so I suspect it's manual?), but generally if you submit a link with a title edited to be less sensational and clickbait-y it gets changed to the linked article title.
Yes, and the OP did abide by HN guidelines. But GGP implied that the title was misleading; but it was the original title! So, what to do if the original title is misleading?
Admittedly this is a twitter thread, so no "actual title" exists.
Personally, I _do_ editorialize by posting a “summary” of what a post discusses, if there’s no real title. I try not to make it pass as my own opinion; sometimes it happened that mods reverted it to the original, less relevant title.
The trick is to write the summary from the point of view of the original author, preferably by lifting a quote from the text.
https://hackernewstitles.netlify.app/ has a recent example "Kevin Scott (MSFT CTO) inviting all Open AI employees to join MSFT" which sounds like the title of a third-party article describing said event, but actually directly points to the Microsoft CTO's tweet with the offer https://twitter.com/kevin_scott/status/1726971608706031670 so it got edited to a quote "If needed, you have a role at Microsoft that matches your compensation" which is an attempt to summarize the content but doesn't provide additional context so it might be condidered more clickbaity https://news.ycombinator.com/item?id=38364315
2/12 is not good, especially if the drives that failed were using off the shelf phison controllers which is basically the entire market besides sandisk/samsung/intel.
They are even among the manufacturers of actual flash memory chips.
> Or do they mainly sell to manufacturers rather than direct to the likes of me?
This. Think they mostly sell OEM SSDs under their name, if you buy a laptop or pre built system from a major manufacturer chances are not that low that you find a SK Hynix SSD in there.
I have a Sabrent M2 in my own PC, bought it because it was the cheapest option. Incidentally I suspect it's the cause of system-wide slowdown in the past few months, even opening the file explorer takes over ten seconds sometimes.
To me the real thing missing is whether those drive advertise power loss protection or not. The next question is whether they are to be used in a laptop where power loss protection is less relevant given the local battery.
That should be irrelevant, because flush is flush right? If your SSD does not write the data after a flush it's violating basic hard drive functionality.
GP has a point in that a laptop is much less likely to experience unplanned power loss because of the built in battery. However that does not help desktops which also use NVME SSDs.
The other problem is that this doesn't only cause problems resulting from power loss. At least some files systems guarantee consistency of data on the drive by flushing at critical points. ZFS on Linux does this. If the flush doesn't happen as promised, subsequent writes could result in corrupted files should something else like a crash interrupt operation.
There is a flood of fake SSDs currently, mostly big brands. I've recently purchased counterfeit 1TB. It passes all the tests, performance is ok, it works... except it gets episodes where ioping would be anything between 0.7 ms and 15 seconds, that is under zero load. And these are quality fakes from a physical appearance perspective. The only way I could tell mine was fake is that the official Kingston firmware update tool would not recognize this drive.
Probably chinese sellers on all those sites. I've noticed a common thread with people who complain about counterfeits is that they're literally buying alphabet soup brand fakes from chinese FBA sellers instead of buying products directly sold by amazon or from more traditional retail channels.
There’s definitely a problem with my grandma or some less-technically educated person buying “alphabet soup” fakes, BUT Amazon does commingle inventory. This means that lots of people can end up with fakes sold by 3rd parties when buying from a reputable brand.
There were even stories of those crazy coupon people reselling on Amazon, and some cases of returned retail products ending up as “new” on Amazon. Which gets problematic with certain things like consumables (the WSJ did an article on toothpastes iirc).
> alphabet soup brand fakes from chinese FBA sellers instead of buying products directly sold by amazon
Does this actually make a difference? I remember the issue was that Amazon would bin devices together regardless if they're from some random third-party or direct sale, so you could have fakes mixed in with genuine and it was basically a lucky dip.
Is this not still the case?
Ultimately, I'd be weary of buying things like this from Amazon and as you suggest go to a more traditional retail channel instead.
Amazon only comingles inventory among FBA sellers, and gives each an option to opt-out from it if they want to. They never comingle 'sold by amazon.com' items. In cases where I've bought amazon.com items and not from FBA sellers I never received bad products, and I've easily bought dozens of SD cards, flash drives, SSDs, etc.
> I've noticed a common thread with people who complain about counterfeits is that they're literally buying alphabet soup brand fakes from chinese FBA sellers instead of buying products directly sold by amazon
AMEN to that !
And the most annoying thing is that those of us who know to avoid FBA is that Amazon have removed the "sold by Amazon" search filter tick-box.
So whilst in the past you could tick a box and be presented with a list of products which are direct-sold rather than FBA, you cannot do that anymore.
According to some Reddit posts, you can still do it if you hack the URL and add an "emi=$obscure_value" GET-param. But I'm guessing sooner or later Amazon will kill this work-around too.
Sold by amazon means "taken out of a box containing fakes and maybe real products". If that's your gamble, may as well buy the fake directly at lower cost.
It doesn't strike me as being a big claim, I recently bought some RAM for a NUC a few weeks ago on Amazon only to determine that it was likely counterfeit. It came in an official box with all packaging intact.
That's interesting. I have a Samsung 990 pro bought on Amazon and have the random lags. I've only noticed it in the terminal, so I figured something else may be the culprit. Never went to 15 secondes, but it can be around 1s.
The Samsung Magician app on Windows reports it as "genuine" and it was able to apply two firmware updates. The only thing it complains about is that I should be using PCIE 4 instead of 3, but I can't do anything about that.
I have been able to fix these random lags by doing multiple full disk reads. The first one will take very long, because it will trigger these lags. Subsequent ones will be much better.
The leading theory I have read is that maintenance/refreshing on the ssd is not done preventative/correctly by the firmware and you need to trigger it by accessing the data.
If you dig at the vendor data stored on the drive firmware, fakes are easy to spot. Model numbers, vendor ID, and serial numbers will be zero’d out or not conforming to manufacturer spec.
I purchased a bunch of fake kingston SD cards in China that worked well enough for the price, but crapped out within a year of mild use. I didn’t lose data. It was as if one day they worked. Then one day they were fried.
Under long term heavy duty, I've routinely seen cheap modern platter outperform cheap brand name NVME.
There's some cost cutting somewhere. The NVMEs can't seem to sustain throughput.
It's been pretty disappointing to move I/O bound workloads over and not see notable improvements. The magnitude of data I'm talking about is 500-~3000GB
I've only got two NVME machines for what I'm doing so I'll gladly accept that it's coincidentally flaky bus hardware on two machines, but I haven't been impressed except for the first few seconds.
I know Everyone says otherwise which is why I brought it up. Someone tell me why I'm crazy
For write loads this is expected, even for good drives, at some level. They tend to have some faster storage which takes your writes and the controller later pushes the changes to the main body of the drive. If you write in bulk the main, slower, portion can't keep up so the faster cache fills and your write has to wait and will perform as per the slowest part of the drive. Furthermore: good drives tend to have an amount of even faster DRAM cache too, so you'll see two drop-offs in performance during bulk write operations. For mainly read based loads any proper SSD¹ will outperform a traditional drive, but if your use case involves a lot of writing³ you need to make more careful choices⁵ to get good performance.
I can't say I've ever seen a recent SSD (that isn't otherwise faulty) get slow enough to say it is outperformed by a traditional drive, even just counting the fastest end of the disk, but I've certainly seen them drop to around the same speed during a bulk write.
[2] get SLC-only⁴ drives, not QLC-with-SLC-cache or just-QLC, and so forth
[3] bulk data processing tasks such as video editing are where you'll feel this significantly, unless your number-crunching is also bottlenecked at the CPU/GPU
[4] SLC-only is going to be very expensive for large drives, even high-grade enterprise drives tend to be MLC-with SLC-cache. SLC>MLC>TLC>QLC…
[5] this can be quite difficult in the “consumer” market because you'll sometimes find a later revision of the same drive having a completely different memory and/or controller arrangement despite the headline model name/number not changing at all – this is one reason why early reviews can be very misleading
I think cheaper QLC chips use a part of their storage space as SLC, which is fast to write. But once you’ve written the fast part that fits in the SLC cache write throughput quickly tanks as it has to push the data further in to the slower QLC parts.
I used to use an HP EX920 for my system drive and it was abysmally slow at syncs. I'd open Signal and the computer would grind to a halt while it loaded messages from group chats. After much debugging, I found out Signal was saving each message to sqlite in a transaction causing lots of syncing.
I found some bash script that looped and wrote small blocks synchronously and the HP EX920 was like 20 syncs/sec and my WD RE4 spinner was around 150. Other SSDs were much faster (it was a few years ago so can't remember the exact numbers)
1) Nobody says otherwise about cheap anything NVMe. They're pretty terrible once they've exhausted the write cache. This is well-known and addressed in every decent review by reputable sites.
2) Sustaining throughput seems the least of our problems when some unknown number of NVMe SSDs might be literally losing flushed data.
I don't know about the 950 pro specifically, but when I bought my 980 pro I looked into this, and it seemed that this drive does have a drop in write speed after a while (can't remember how long) but "low speed" wasn't that low. Again, don't remember specifics, but it was above 1 GB/s. Other drives fared much worse, with a drop coming in sooner and going lower.
Depending on your needs this can be an issue.
For me, using this drive for random "office" work, I figured I'd never feel it in practice. This drive is supposed to support PCIE 4, but my laptop only does 3. This also "helps", since it won't fill whatever cache it uses as quickly. In practice, it was able to write 100 GB at the top speed. Didn't bother to test more. The only time I've ever written that many data at a time was restoring a backup when I bought the drive. Since my backup was on 2.5" spinning rust, it wasn't an issue.
I think it's important to be able to have a rough idea of how you'd be using this. If this drop in performance means I could use a cheaper drive, I'm all for it.
But some drives are truly awful. My work laptop came with a cheap Samsung drive that would quickly drop to around 200 MB/s. At first, I thought I had somehow badly configured Linux or something (I'm running zfs with native encryption).
Then I went and checked my desktop running quite worn-out SATA ssds from ~2012 (840 evo) and those drives would wipe the floor with the NVMe in write performance. They wouldn't go below 400 something MB/s until almost full. Same kernel version and zfs config.
It would seem that this is quite common behavior in cheap drives. But I guess that if all you do is browse the web, write mails in outlook and type the occasional word document, you're still ahead of spinning rust for the durability (it won't break if you drop your laptop) and for the latency.
In my use case I'm talking about arrays of them, think 8. RAID can parallelize platter really nicely in that configuration. But on modern ram/cpu (epyc 9654s), you'll still see the disk dragging you down. NVME drags me down more.
Maybe the key is a bunch of small ones. Like 20 512GB modules... That may be brilliant. It's way cheap
Or just get some Kioxia CD8 or CD8R or similar from Samsung/ Solidigm/ Micron depending on what you need. It will be much faster than spinning rust in all situations I am quite sure.
Decent SSDs have a huge latency advantage compared to even the best HDDs just out of principle. Enterprise SSDs focused on read-write workloads can sustain decent performance even under continuous 100% load. For example: https://apac.kioxia.com/en-apac/business/ssd/data-center-ssd...
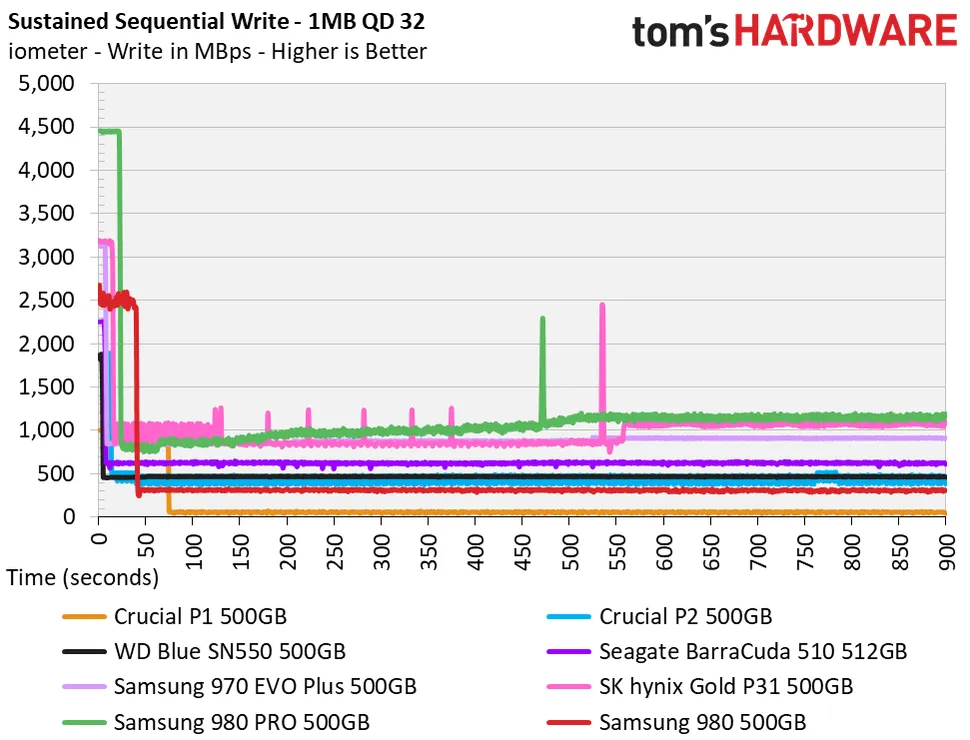
In a 900 second timeframe, the 980 Pro drops down to a bit above 1GB/s, while the worst is somewhere in the tens of MB/s. So there are significant differences in SSD performance profiles which you can only find out about from reviews like this.
This was the kind of review I was talking about. But you should also look at the specific capacity you're after. IIRC for the 980 non pro the 1 TB is better than the smaller ones.
That sounds like you might be having quite specific needs. Some reviews have graphs showing how the drives behave in various situations, so that could help you.
However, what I've found perusing those reviews is that there's a huge price gap between this class of drives (9x0 pro, wd 8xx and the like) and "enterprise" drives which seem to have more stable performance.
Writes are completed to the host when they land on the SSD controller, not when written to Flash. The SSD controller has to accumulate enough data to fill its write unit to Flash (the absolute minimum would be a Flash page, typically 16kB). If it waited for the write to Flash to send a completion, the latency would be unbearable. If it wrote every write to Flash as quickly as possible, it could waste much of the drive's capacity padding Flash pages. If a host tried to flush after every write to force the latter behavior, it would end up with the same problem. Non-consumer drives solve the problem with back-up capacitance. Consumer drives do not have this. Also, if the author repeated this test 10 or 100 times on each drive, I suspect that he would uncover a failure rate for each consumer drive. It's a game of chance.
The whole point of explicit flush is to tell the drive that you want the write at the expense of performance. Either the drive should not accept the flush command or it should fulfill it, not lie.
(BTW this points out the crappy use of the word “performance” in computing to mean nothing but “speed”. The machine should “perform” what the user requests — if you hired someone to do a task and they didn’t do it, we’d say they failed to perform. That’s what’s going on here.)
The more dire problem is the case where the drive runs out of physical capacity before logical capacity. If the host flushes data that is smaller than the physical write unit of the SSD, capacity is lost to padding (if the SSD honors every Flush). A "reasonable" amount of Flush would not make too much of a difference, but a pathological case like flush-after-every-4k would cause the SSD to run out of space prematurely. There should be a better interface to handle all this, but the IO stack would need to be modified to solve what amounts to a cost issue at the SSD level. It's a race to the bottom selling 1TB consumer SSDs for less than $100.
I still don't think this is the problem, the drive can just slow down accepting writes until it has reclaimed enough space.
The bigger problem is manufacturers chasing the performance. Generally you get the feeling they just hit their firmware with a hammer so it barely doesn't break NTFS.
See also the drama around btrfs' "unreliability", which is all traced back to drives with broken firmware. I fully expect bcachefs will get exactly the same problems.
Yeah, but then you have a write amplification problem. Padding is write amplification from the start, and then GC is invoked many more times than it otherwise would be. There is a fundamental problem with (truly) flushing an IO that is smaller than the media write unit. It will cause problems if "abused." The SSD either needs to take on the cost of mitigation (e.g. caps) or it needs some way to provide hints to the host that don't exist today.
I'm curious what the real cost of power protection is for the manufacturer. Adding caps or a bit of backup power seems like it _should_ be a fairly cheap compromise to maintain performance without lying about persistence
M.2/2280 makes it hard. Can't use cheaper aluminum can capacitors due to their size/height. The low profile (tantalum?) capacitors are expensive and take up a lot of PCB area, forcing a two sided PCB design on 2280 (the 110mm version would be better here). M.2 only provides 5V. On other form factors you get 12V and can get more charge stored for the same capacitance (q=CV) without needing a DC-DC converter.
For a $20 device this is 5-25% of the cost the product, assuming $40 retail cost. It would be 1-5% for a $100 product, of course.
You would pay for a such device, but 99% of people wouldn't. Now you have a product which costs 5-25% higher than all your competitors and in the world where the price dictates the sales you have no opportunity to sell your product.
NB to be sure on the prices I've checked Amazon. There are SSDs what are cheaper than many mounting trays, enclosures (without drives) and tray kits.
I'm not so sure price is the only competing factor for SSDs. Devices generally also differentiate on performance as well. Even on consumer-oriented Slickdeals forum (where people are posting deals) there's pretty extensive breakdowns comparing different SSDs (controllers, flash, cache design). This has been floating around for a while https://www.reddit.com/r/NewMaxx/comments/dhvrdm/ssd_guides_...
Whether consumers would actually pay more for a device with power protection is unclear.
This is the whole point of a FLUSH though. You expect latency penalties and worse performance (and extra pages) if you flush, but that's the expected behaviour: not for it to (apparently) completely disregard the command while pretending like it's done it.
> Non-consumer drives solve the problem with back-up capacitance.
I’m pretty sure they used to be on consumer drives too. Then they got removed and all the review sites gave the manufacturer a free pass even though they’re selling products that are inadequate.
Disks have one job, save data. If they can’t do that reliably they’re defective IMO.
Yes, GC should be smart enough to free up space from padding. But then there's a write amplification penalty and meeting endurance specifications is impossible. A padded write already carries a write amplification >1, then GC needs to be invoked much more frequently on top of that to drive it even higher. With pathological Flush usage, you have to pick your poison. Run out of space, run out of SSD life.
This is the only correct answer, if you don't like the boss of a social media company, you should just cut all ties with everyone on there. Then lock yourself into your room, never go outside again, and complain about it on HN.
Fix everything that makes Mastodon a terrible user experience, get me and all the people I want to reach an invite to Bluesky or persuade people to start using Threads, and I'll happily switch.
You seem to be claiming that everyone still on Twitter is ideologically compromised. There's a ton of people just ignoring the politics and I still need a channel to reach them.
Yet again monetary selfishness wins over principle.
Maybe you should stay on Twitter.
Edit: Based on your website, who exactly are you trying to reach? Prospective clients? On Twitter?
You say "users of your app", but it seems like that isn't a huge volume of people, and were you to move to Bluesky, they would almost certainly follow... Unless it's not worth it for them?
The attempt is not persuasion, but alienation. This is the fate of people who behave as he does, and I believe will contribute (to the extent any one person can) in deterrence of others from trying to normalize continued Twitter usage in light of its antisemitic shift in tone.
Alienation from what? People who uncritically parrot fabrications and propaganda on HN?
THAT is what shouldn't be "normalized".
But since you brought it up, of all the indicators of societal descent over the last 7-10 years, the shift away from critical analysis and open dialogue to soviet-level information control and behavior/thought policing is most troubling.
I use Twitter daily because it's the only platform where I have a chance to hear the whole truth on a given subject, usually assembled from multiple sources. I follow a lot of actual leftists as well as the conservatives and liberals-in-exile that make up the modern "right".
I don't know that I follow anyone with whom I agree on every topic, and that's as it should be IMO. Even when I strongly disagree, I'm grateful for the freedom to hear and evaluate these voices.
And while I'm reluctant to engage with your "argument", I'll say that I've seen a handful of antisemitic posts over 10+ years on Twitter, none recently. I have seen a fair amount of anti-Israel and anti-Zionist content in the last six weeks, consistently from those on the left and consistent with what I've seen in demonstrations around the world.
The continued use of Twitter ought to be met with disdain by anyone with a modicum of integrity. It is each person’s duty to make that clear to those who seem to lack the ability to self regulate, morally.
You don’t get to support a hateful platform consequence free.
iirc, twitter turned off all anonymous access, unless you come from a search engine, then you get a limit number of requests. So zedeus came up with an idea to make a massive pool of search engine'd api tokens and use those to keep nitter up. The mirrors would have to copy that idea, and few (0?) have atm.
The current state is to use guest accounts [1]. If you use that branch instead of master and get a collection of accounts, you can run your own instance. For my personal use instance this is working fine with the initial set of accounts I put in. No idea how long this will work and/or when it is going to get merged, it is a moving target.
I think the token workaround you mentioned is the old way that no longer works, but I am not sure.
The models that never lost data: Samsung 970 EVO Pro 2TB and WD Red SN700 1TB
Correction: “Plus” not “Pro”. Exact model and date codes:
Samsung 970 Evo Plus: MZ-V7S2T0, 2021.10
WD Red: WDS100T1R0C-68BDK0, 04Sept2021
Update 2: models that lost writes:
SK Hynix Gold P31 2TB SHGP31-2000GM-2, FW 31060C20
Sabrent Rocket 512 (Phison PH-SBT-RKT-303 controller, no version or date codes listed)
Thanks, the 970 Evo Plus is a solid unit. I have one in my old PC, along with a 980 Pro. Went 990 Pros on my new, they didn't go 30 minutes before I had the firmware updated. :-) Very good performers.
(I always keep an eye on things like firmware updates).
Does advertising a product as adhering to some standard, but secretly knowing that it doesn't 100%, count as e.g. fraud? I.e., is there any established case law on the matter?
I'm thinking of this example, but also more generally USB devices, Bluetooth devices, etc.
Anyways, not in the US where you're probably asking for, but yes, the vast majority of the developed word has that. It's called "false advertising", and exists at least in the EU, Australia, UK. You can't put a label on your product or advert that is false or misleading.
So if the box says this is a WiFi6E router, but it's actually only 5 because it's using the wrong components to save on costs, you can report them to the relevant authority and they'll be fined (and depending on the case and scenario you get compensation). The process is a harder bordering on the impossible if you bought from AliExpress from a random no name vendor though, but as long as the vendor or platform or store exists in the country with the sensible regulation you can report it.
That’s not really what the commenter was asking. That’d be false advertising in the US too.
I think the question is less “if they skip on parts and lie” and more along the lines of incompleteness. Like “it’s an HTTP server, but they saved on effort and implement put as post, which works fine for most of use cases”.
That said, I’d guess this would be a pretty hard case to win. The law typically requires intent when false advertising, so if they didn’t know they didn’t follow the spec they might be fine. And it depends on the claims and what the consumer can expect. Like, if you deliberately don’t say explain the exact spec your SSD complies with, and you make no explicit promises of compatibility, it’s a harder win. Like I bet few SSD manufacturers will say “Serial ATA v3.5 (may 2023) tested and compatible with OpenXFS commit XYZ on Debian Linux running kernel version 4.3.2”. But if they say “super fast SSD with a physical SATA cable socket”, then what really was false if it doesn’t support the full spec?
I was under the impression that a lot of off-brand USB devices didn't use the USB logo specifically to get around certification requirements. Basically, they just aren't advertising adherence to a standard. No idea about NVMe or BT.
Actually, I think that one has technical merit - the SD card spec includes non-storage IO - https://en.wikipedia.org/wiki/SD_card#SDIO_cards - that isn't supported by slots that only care about storage. At least, that's my understanding of the situation.
Hardware vendors are known to swap to cheaper lower performance hardware after reviews are out which in my eyes is fraud, whether or not the law agrees is a different story.
Samsung was caught doing this with their 970 pro( plus? Their naming is awful) - they swapped out the controller in a good portion of devices which resulted in significantly lower read and write performance.
Not a lawyer, but I doubt it – otherwise you might have a case against Intel and AMD regarding Spectre and Meltdown?
It might be a different story if the spec was intentionally violated, though (rather than incidentally, i.e. due to an idea that should have been transparent/indistinguishable externally but didn't work out).
"Oops we didn't mean to do that" isn't a defense from liability for product not doing what you told the purchaser it would.
It's their responsibility to do develop the product correctly, do QA, and if a defect is found, advise customers or stop selling the defective goods.
The greatest scam the computer industry pulled was convincing people that computers are magical, unpredictable devices that are too complex for the industry to be held responsible for things not working as claimed.
To be fair, I’m not even sure if the majority of consumers would prefer a “power outage safe” SSD that is however significantly slower over the alternative.
I do agree that there should be transparency, though: Label it “turbo mode”, add a big warning sticker (and ideally a way to opt out of it via software or hardware), but don’t just pretend to be able to have the cake and eat it too.
Merchantability and implied fitness? You absolutely could try sue the in small claims court for damages.
For extra fun: if the box carries a trademark from a standards group, you could try adding them into the suit; use of their trademarked logo could be argued to be implied fitness, if there are standards the drive is supposed to meet to use it.
At the very least they might get tired of the expense of the expense of sending someone to defend the claim, and it would cease to be profitable to engage in this scammery.
I would probably use stronger words than that, data persistence is a big deal, so the missing part of the spec is a fundamental flaw. What's a disk whose persitence is random? You can probably legally assail the substance of the product.
I think it's more or less the same thing, the recall is the way to legally prove you didn't intend to disseminate the flawed product, wheras leaving it on the market after learning of the problem shows intent to keep it there. I would be surprised if a discovery at those companies would not surface an email form engineers discussing this problem.
> Wondering if anything changed since the original tests...
You're wondering if firmware writers lie to layers higher up in the stack? I think it's a 100% certainly that there's drive firmware that lies.
There's a reason why many vendors have compatibility lists, approved firmware versions, and even their "own" (rebranded from an OEM) drives that you have to buy if you want official support (and it's not entirely a money grab: a QA testing infrastructure does cost money).
Meanwhile I'm over here jamming Micron 7450 pros into my work laptop for better sync write performance.
I have very little trust in consumer flash these days after seeing the firmware shortcuts and stealth hardware replacements manufacturers resort to to cut costs.
Have a solid vendor for these that isn't insanely priced (for home use)? The last couple I tried to buy they sent 7300's and tried to buy me off with a small refund (eBay).
I wonder how much perf is on the table in various scenarios when we can give up needing to flush. If you know the drive has some resilience, say, 0.5s of time it can safely writeback during, maybe you can give up flushes (in some cases). How much faster is the app then?
It's be neat to see some low-cost improvements here. Obviously in most cases, just get an enterprise drive with supercapa or batteries onboard. But an ATX power rail that has extra resilience from the supply, or an add-in/pass-through 6-pin sata power supercap... that could be useful too.
If the write-cache is reordering requests (and it does, that's the whole point), you can't guarantee that $milliseconds will be enough unless you stop all requests, wait $milliseconds, write your commit record, wait $milliseconds, then resume requests. This is essentially re-implementing write-barriers in an ad-hoc, buggy way which requires stalling requests even longer.
Flush+FUA requires the data to be stored to non-volatile media. Capacitor-backed RAM dumping to flash is non-volatile. When a drive knows it has enough capacitor-time to finish flushing all preceding writes from the cache, it can immediately say the flush was completed. This can all be handled on the device without the software having to make guesses at how long something has to be written before it's durable.
Performance gains wouldn’t be that large as enterprise SSDs already have internal capacitors to flush pending writes to NAND.
During typical usage the flash controller is constantly journaling LBA to physical addresses in the background, so that the entire logical to physical table isn’t lost when the drive loses power. With a larger capacitor you could potentially remove this background process and instead flush the entire logical to physical table when the drive registers power loss. But as this area makes up ~2% of the total NAND, that’s at absolute best a 2% performance benefit we are potentially missing out on.
> (and the lower level equivalents in SATA, NVMe etc.)?
This is not a technical problem that needs yet another SATA/SAS/etc command to be standardized. It's a 'social' problem that there's no real incentives for firmware writers to tell the truth 100% of the time.
The best you can hope for is if you buy a fancy-pants enterprise storage solution with compatibility lists and approved firmware versions.
The DRAM cache does not hold user data. It holds the flash transition layer that links LBAs to NAND pages. Higher performance drives use 1GB of DRAM per 1TB of NAND. In cheap DRAM-less drives if the I/O to be serviced is not cached in the 1MB or so of SRAM it has to do a double lookup. Once to retrieve the full FTL table from NAND and a second lookup to actually service the I/O.
It'd be nice if there were a database of known bad/known good hardware to reference. I know there's been some spreadsheets and special purpose like the USB-C cables Benson Leung tested.
Especially for consumer hardware on Linux--there's a lot of stuff that "works" but is not necessarily stable long term or that required a lot of hacking on the kernel side to work around issues
SK Hynix is the #3 flash manufacturer (acquired Intel's NAND biz), and their RAM is quite decent. i wouldn't think twice about buying if it wasn't for this report.
Pretty much every brand uses phison controllers in at least some of their products, even wd/samsung/intel who design controllers in house use them for their cheapest offerings because phison is all about making the cheapest product possible.
This has always been the case? At least it was a course learning when we wrote our own device drivers for minux, even the controllers on spinning metal fib about flush.
If stuck with consumer drives, you can add cheap PLP via riser cards that have a supercapacitor. Here's a post on the TrueNAS forums that tested one out.[1]
Cheap drives don't include large dram caches, lack fast SLC areas, and leave off super-capacitors that allow chips to drain buffers during a power-failure.
The bottom answer especially states that "blockdev --flushbufs may still be required if there is a large write cache and you're disconnecting the device immediately after"
The hpdarm utility has a parameter for syncing and flushing device buffers themselves. Seems like all three should be done for a complete flush at all levels.
I'd be curious how well it actually correlates. It would be hard to make the most performant system that's always consistent with flushed data but there are probably a lot of firmwares out there with untested performance ideas, etc.
We're talking about scenarios where the drives report (untruthfully) that the data has been committed to non-volatile storage _before_ the power is removed
Not scenarios where the data is in the cache when the power drops and the drive is expected to write out the cache with internal power alone.
The second scenario is what's standard in enterprise class drives used with RAID controllers, the controller reports 'committed' to the OS and _then_ commits the data, it can do this because the path to nonvoltatile storage downstream of the controller has redundant power (the raid controller has a battery backup and the disks have their own battery backups, as well as control logic that guarantees data in the cache makes it to nonvolatile if the power drops out)
The first scenario is for consumer disks, they don't report 'committed' until the data is actually committed. That makes them a whole assload slower. (Unless they lie.)
Looking up the definitions of write-back vs write-thru caching will help you out here
The Flush command shall commit data and metadata associated with the specified namespace(s) to non-volatile media. The flush applies to all commands completed prior to the submission of the Flush command.
No. One is a lie. The other is an attempt at fault tolerance. The later will not claim something that isn’t true, but it will try to do what you want, as a user, as a nice gesture.
{kind=link}