these or some of the deeply embedded standard convictions we need to get rid of. We simply don't know.
The short answer is that of cause LLMs can come up with something new: They can learn to rationalise – the simplest example is learning to add numbers.
So pedantically speaking, the quote is straight up wrong.
I took that more to mean that most LLMs won't spontaneously produce new insights given a general topic ("a paper about Middlemarch" being the example given). Their default mode is just to barf out somewhat patronizing summaries or answer questions with dry facts (and occasional factual-sounding nonsense).
It takes coaxing (and some cherry-picking) to get anything creative out of LLMs -- and some people suspect newer versions are so locked-down to avoid sounding "scary" that they actively avoid saying anything too interesting or philosophical.
The line between "creative output" and "hallucinated madness" is also somewhat blurry (for humans and LLMs alike...)
>It takes coaxing (and some cherry-picking) to get anything creative out of LLMs
I assume by LLMs you actually mean "ChatGPT and similar commercial LLM services". Raw LLMs like LLaMA and Falcon will happily spout out the craziest, sometimes super creative ideas, it's just the lobotomising of ChatGPT and the like that destroys their creativity.
Well, it's a tradeoff, RLHF also makes ChatGPT better at some tasks like instruction following. "lobotomising" makes it sound like there are only downsides
I've gotten them to be creative in ways that were unexpected, like outputting tokens that have absolutely no (obvious) relation to the current conversation
While trying to iterate on a name for a product, I had it output an internal monologue alongside outputting name ideas.
With each iteration of naming I'd ask it to probe its understanding in of human creativity and list how the usefulness/realism of the internal monologue.
After a few loops the internal monologue started modeling fleeting memories about things like "that time at camp where X happened".
Eventually it was modeling fleeting thoughts like "the warmth of the cup of coffee on the desk" as a source of inspiration, and random observations like "it looks like traffic is picking up outside, getting to yoga will take a while" in the middle of a name generation task
Technically it's a hallucination generator, but I think you described why I made it (creativity and hallucinations really are similar for both LLMs and humans)
In the quote the author is speaking about students handing in an assignment and using ChatGPT to write it. He says:
> This may not count as plagiarism, but it won’t produce anything new.
First, it is plagiarism by definition. Any time one presents work as their own which they did not create themselves is plagiarism .
Second, and vastly more importantly going forward, students were never handing in “new” ideas on an assignment. Using an LLM to generate a “pastiche” that is then read by the student (hopefully) before being handed in is still a win in my book. Having students ask their questions to an LLM can be an amazing tool to further learning but when students and educators are terrified of this new tool they will hide their usage of it and then it becomes a tool for copying rather than learning and plagiarism is the only consequence.
There's a bit of a motte-and-bailey situation here - the student clearly plagiarized if they passed off ChatGPT's work as their own, but this has no bearing on the more interesting question of whether ChatGPT itself "plagiarizes" from its training set or creates new knowledge by synthesizing it.
>Any time one presents work as their own which they did not create themselves is plagiarism .
Not sure this is true. If I hand in an assignment that is written strictly by scattering chicken bones into a grid representing the most common English words and writing down the result is that plagiarism? It will definitely be non-sense, but i'm not copying anyone else's work.
chatGPT is just a more sophisticated chicken bone grid.
> The short answer is that of cause LLMs can come up with something new:
Well, yes. They produce random output that adhere to statistical models.
I had ChatGPT 3.5 produce a wonderful whimsical portrait interview of a couple breeding Giant Tibetian Hamsters for home protection in Norwegian.
> They can learn to rationalise – the simplest example is learning to add numbers.
Certainly not? Composite systems that leverage LLMs can do a lot of things - but AFAIU LLMs will likely never rationalize or be able to "add numbers" in the normal sense; they can count only in as much they know that 1,2,3,4 is more probably coming after "count to four" than 10,2,4.
> but AFAIU LLMs will likely never rationalize or be able to "add numbers" in the normal sense; they can count only in as much they know that 1,2,3,4 is more probably coming after "count to four" than 10,2,4.
The question is does a model trained on move sequences in a game of othello just learn "play X(t) after seeing the sequence X(t-3), X(t-2), X(t-1)" or does it build a representation of the board and use that to choose the next move to play.
> Certainly not? Composite systems that leverage LLMs can do a lot of things - but AFAIU LLMs will likely never rationalize or be able to "add numbers" in the normal sense;
This implies we know what “rationalising” actually is, which we don’t. There’s no reason to believe that our brains don’t operate in fundamentally the same way as LLMs. There’s no reason to think that the LLM approach to reasoning is any less valid than the “normal” way, whatever that even means.
>Certainly not? Composite systems that leverage LLMs can do a lot of things - but AFAIU LLMs will likely never rationalize or be able to "add numbers" in the normal sense; they can count only in as much they know that 1,2,3,4 is more probably coming after "count to four" than 10,2,4.
LLMs can add numbers just fine. arithmetic is one of the easiest domains to test on data it'd never have seen in training.
I can see what you are getting at, but the underlying implementation of LLMs really is reliant on non-deterministic, random sampling of the underlying model. The random sampling is weighted to favor certain selections over others, but rare selections are possible.
Its intrinsically built on a degree of randomness. Though it is also unfair to say something like "produce random output" as the probabilities themselves make it less than fully random.
I don't know why this mistake gets repeated, but NNs are universal continous function approximators. They can't approximate non-continuous functions in general, and there are plenty of non-continuous computable functions.
Also, this theorem is almost useless in practice: it only tells you that, for any function and desired error rate, there exists some NN which would approximate that function within that error rate. But there is no proof that there is some way to train the weights for that NN based on any known training mechanism, even if we magically knew the shape of that NN (which we don't). Obviously, since we don't know if an algorithm to train the NN even exists, we have even less idea of how long it might take, or how large the training set would have to be.
So this theorem doesn't really help in any way answer whether our current AI techniques (of which training is a fundamental component) could be used to approximate human reason.
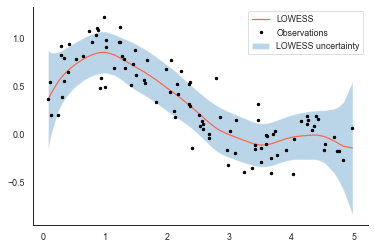
The whole article smells like bad science. Just looking at the first plot, you can immediately see something is off. LOESS CIs are a bit tricky, but here either the model is completely wrong or the CI calculation is. So the trend is definitely not as significant as they make it out to be. A realistic 95% CI would look like this: https://james-brennan.github.io/img/lowess1_22_1.png
What does it mean to learn to add numbers? LLMs in general are not good at accurately portraying their own processes, and humans are equally bad at interpreting what LLMs do “under the hood”.
“To rationalize” means something like “to provide a reason (a rationale)” and I don’t think the current generation of models can do that.
You're right that LLMs can produce new knowledge, but you're misinterpreting the quote. The claim in the article is that LLMs won't produce anything new when asked for "a paper about Middlemarch". The rest of the article goes on to demonstrate how language models can create new knowledge.
{kind=link}
these or some of the deeply embedded standard convictions we need to get rid of. We simply don't know.
The short answer is that of cause LLMs can come up with something new: They can learn to rationalise – the simplest example is learning to add numbers.
So pedantically speaking, the quote is straight up wrong.