For those wondering why this is interesting: This technique is being used to reproduce[0] the Alpaca results from Stanford[1] with a few hours of training on consumer-grade hardware.
I believe there will soon be a cottage industry of providing application-specific fine-tuned models like this, that can run in e.g. AWS very inexpensively. The barrier today seems to be that the base model (here, Meta's LLaMA) is encumbered and can't be used commercially. Someone will soon, I'm confident, release e.g. an MIT-licensed equivalent and we'll all be off to the races.
Today Databricks announced [0] 6b parameter model from EleutherAI finetuned on Alpaca dataset. According to their CEO[1], training took 3 hours, and costed $30. They didn't release any details on how it was trained, but likely with LoRa.
I haven't done any formal tests on this yet, but with llama-13b, the overall structure of its responses definitely becomes much more ChatGPT-like. It would be very interesting to see how the 65B model performs.
The 1/2 month seems to match Lycoris/LoCon, which as I understand (haven’t dug into the details on this) is a newer refinement of LoRa. LoRa has been used for longer, correct.
The LyCORIS/LoCon repo started committing 1 month ago and almost no one is using it except for a few experiments (not even the automatic webui supports it without a plugin).
Judging from activity on Civitai, I think “almost no one is using it except for a few experiments” is very wrong. Sure, A1111 needs a plugin for it; it needs a plugin for ControlNET, too, but that is also quite popular.
I'm also judging from the activity on CivitAI, the most downloaded (>1000 downloads, not many) ones are actually just LoRA with LoCon in another (experimental) branch of the CivitAI page, definitely not "very wrong" ahah
>it needs a plugin for ControlNET
The big difference is that ControlNet actually required a pretty complex interface to be used effectively, meanwhile the use of LoCon/LyCORIS should be completely transparent and works like a LoRA
ControlNet is built in as of maybe two weeks ago and no longer requires an extension. I started using it when the built-in support arrived and have had a lot of fun with it since.
4 months? I don't think so, people really start using LoRA when it was added to the diffusers library less than 2 months ago, this library is used by the training plugin of automatic webui, I guess time seems to flow more slowly when many things happen.
> This technique is being used to reproduce[0] the Alpaca results from Stanford[1]
Reproduced is a strong statement, without any rigorous justification other than a few cherry-picked examples. Alpaca-LoRA is simply LLaMA with LoRA-tuning on the Alpaca data. There are no metrics, no measurements, no evaluations to show that the Alpaca-LoRA performs similarly to Alpaca, when it is well-known in the field that parameter-efficient fine-tuning always pays a cost in terms of performance relative to full fine-tuning (which is what Alpaca does).
(This has been a huge nit for me because of the recent flood of Alpaca-replications, or even claims that Alpaca comparable to ChatGPT, rushing to market themselves, but with nothing to justify their claims.)
>when it is well-known in the field that parameter-efficient fine-tuning always pays a cost in terms of performance relative to full fine-tuning
The LoRA paper clearly states the performance of the method "LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. ": https://arxiv.org/abs/2106.09685
I don't want to get into the weeds of the subtleties of evaluation, hyperparameter-tuning and model comparisons, but let's just say that subsequent studies have shown that LoRA (consistent with most parameter-efficient tuning methods) underperform full fine-tuning: https://arxiv.org/abs/2203.06904
As simple way to think about it is this: if LoRA really gives full fine-tuning performance, why would anyone ever fully fine-tune a model?
To balance my view a little, it is definitely a valid question to ask "how far can we get with parameter-efficient tuning", and I firmly believe that as models get larger, the answer is "very, very far".
That said, I also dislike it when it is carelessly claimed that parameter-efficient tuning is as good as full fine-tuning, without qualifications or nuance.
It is not apparent to me that fine tuning should be better, especially since the LoRA method seems like it could be robust against catastrophic forgetting.
I agree - my comment originally had a parenthetical about this fact, but I thought it was probably confusing to people who just wanted to understand what this was about. Perhaps I shouldn't have edited it out.
It also bothers me that a lot of LoRA claims read like "You won't believe how little it costs to train these models!", when of course 99%+ of the complexity and cost is in the LLaMA (or whatever) model that underpins it. Folks are talking about it in a loose way that implies some kind of miraculous overall training cost breakthrough.
There’s a not insignificant intersection of projects and developers who might be using both LoRA and LoRa at the same time. What a terrible name collision. Hopefully this doesn’t become one of the foundational terms in AI that everyone must use frequently like “Transformer”.
Isn't there something really perfect about people working on a language model either not trying or outright failing to use that language model to tell them if their project name already exists?
On their github they reference a related project called "HuggingFace" so you know the sky's the limit with the names in this field, could have been called anything else really.
> On their github they reference a related project called "HuggingFace"
Quick jargon literacy boost: "HuggingFace" is a platform tailored to hosting and sharing ML repositories -- like Github for AI. The parent company, "Hugging Face", is also in and of itself a major contributor to several AI research projects & tooling.
Ironically, they still managed to hit a namespace collision... albeit self-inflicted.
the actual platform is called "HuggingFace Hub". The company itself is called "HuggingFace" or "Hugging Face" (I have seen it referred to in both ways, I am unsure which is officially correct). There is no namespace collision.
Is this really a big problem? LoRa is a telecom thing. LoRA is a machine learning thing. Yeah, they're adjacent industries but still seems different enough to make it pretty easy to distinguish. I had never heard of the LoRa alliance until you mentioned it in this comment.
Unfortunately, no. It's even worse within the video game industry. I'm not just talking Doom 4, er, Doom (2016). The upcoming sequel to 2014's Lords of The Fallen? Well that's called Lords of The Fallen. They didn't even get 2 game in before repeating the exact same name.
Can someone ELI5 "LoRA reduces the number of trainable parameters by learning pairs of rank-decompostion matrices while freezing the original weights"?
LoRA finds a subset of the original weights (about 1%) which can be trained to achieve about the same result as training the whole model while using 100x less compute.
Original weights frozen = Rather than modify the original model, the training results are saved to a small file of only a few MB.
In practice this means you can fine tune a 30B parameter model on a consumer GPU in a couple of hours. Without LoRA you would need to run multiple expensive data center GPUs for days or weeks.
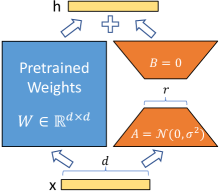
To be more exact, LoRA adds two matrices `A` and `B` to any layers that contain trainable weights. The original weights (`W_0`) have the shape `d × k`. These are frozen. Matrix `A` has dimensions `d × <rank>` (`rank` is configurable) and matrix `B` has the shape `<rank> × k`. A and B are then multiplied and added to `W_0` to get altered weights. The benefit here is that the extra matrices are small compared to `W_0`, which means less parameters need to be optimized, so less activations need to be stored in memory.
Ah, so the resulting model contains both the large matrix of original weights, and also the two small matrices of alterations? But this is smaller than the alternative of a model which contains the large matrix of original weights, and an equally large matrix of alterations.
Why is fine-tuning done with separate alterations, rather than by mutating the original weights?
> Why is fine-tuning done with separate alterations, rather than by mutating the original weights?
The goal of most parameter-efficient methods is to store one gold copy of the original model, and learn minor modifications/additions to the model. The easiest way to think about this is in some kind of deployment setting, where you have 1 capable model and you learn different sets of LoRA weights for different tasks and applications.
The original intent of parameter-efficient methods is to reduce the amount of storage space needed for models (do you really want to keep a whole additional copy of LLaMA for each different task?). A secondary benefit is that because you are fine-tuning a smaller number of parameters, the optimizer states (can take up to 2x the size of your model) are also heavily shrunk, which makes it more economical (memory-wise) to (parameter-efficient) fine-tune your model.
> But this is smaller than the alternative of a model which contains the large matrix of original weights, and an equally large matrix of alterations.
It's actually larger. If you just have two equally large matrices of the same dimension, one original, and one of "altercations"... then you can just add them together.
> Why is fine-tuning done with separate alterations, rather than by mutating the original weights?
Then you'd have to compute the gradients for the whole network, which is very expensive when the model has 7b, 65b, 165b parameters. The intent is to make that cheaper by only computing gradients for a low rank representation of the change in the weight matrix from training.
Correct me if I'm wrong, but I think you still need to compute gradients of non-trained weights in order to compute the gradients of the LoRA weights. What you don't have to do is store and update the optimizer state for all those non-trained weights.
I mean the derivative of a constant is 0. So if all of the original weights are considered constants, then computing their gradients is trivial, since they’re just zero.
Computing gradients is easy/cheap. What this technique solves is that you no longer need to store the computed values of the gradient until the backpropagation phase, which saves on expensive GPU RAM, allowing you to use commodity hardware.
It's larger, but there are less parameters to train for your specific use case since you are training the small matrix only, while the original ones remain unaltered.
Per the original paper, empirically it’s been found that neural network weights often have low intrinsic rank. It follows, then, that the change in the weights as you train also have low intrinsic rank, which means that you should be able represent them with a lower rank matrix.
Edited: By the way, it seems to me that there is an error in the wikipedia page because if the Low-rank approximation takes a larger rank then the bound of the error should decrease, and in this page the error increases.
>> that the change in the weights as you train also have low intrinsic rank
It seems that the initial matrix of weights has a low rank approximation A and this implies that the difference E = W - A is small, also it seems that PCA fails when E is sparse because PCA is designed to be optimum when the error is gaussian.
kinda/yes. To translate to more intuitive concepts: the matrices don't contain much variance in as many degrees of freedom as they could.
Think of a point cloud of a piece of paper floating in the wind. It would be a 3xn list of points, but "really" it's a 2d piece of paper.
Just like I can rewrite the number 27 as 333 or 8+19 or (2^3)+(2^4)+3.. Given a single matrix one can find myriad ways to rewrite it as a sequence of matrices that have the same (or similar) numeric value, but with interesting or desirable properties. :D
My favorite example (which is used in signal processing) is to take your ugly matrix and rewrite it as a set of smaller matrices where most of the elements are zero, or a power of 2.
It turns out, computers can multiply by zeros and powers of two very fast
>In practice this means you can fine tune a 30B parameter model on a consumer GPU in a couple of hours.
Consumer GPU, yes, but in practice LoRA doesn't actually reduce training time. What it mainly reduces is memory requirements. In fact LoRA training can often require more training steps than full fine-tuning and therefore be slower (you can imagine why this is the case: the optimization is trying to modify the mode's behavior a smaller number of parameters, and so has a harder job)
Is what still useful? A LoRA is about as good and useful as a full fine tune. If you have unlimited storage space to store them or unlimited compute to make them then I would still prefer full fine tunes. But the difference is marginal and generally not worth the storage space or increased compute costs for individuals.
The insight is that we don't need to modify a lot of parameters to get a generally competent model to do well on specific tasks. When you have a linear layer with a weight matrix of dimension d_in x d_out, the change you undergo during full finetuning is also a matrix of d_in x d_out, which can be huge. We represent the latter using two matrices of shape d_in x r and r x d_out. You save a lot of parameters when r is small. So when you use it, the input goes through two streams 1) the orignal frozen weight turning a vector of size d_in to d_out and 2) the low-rank weights turning a vector of size d_in to r and r to d_out. The two streams are then summed together. (There's a figure in the paper.)
This way of doing thing is nice for a few reasons. It's easy to parallelize. You can change r to control how many parameters to train. You can also merge the low-rank weights with the original one to avoid latency.
Note that we don't select a subset of the original parameters. We train extra ones.
What is the difference to training an adapter? Or to adding a new task specific layer [0]? Has it been demonstrated that LoRA works best out of all of these approaches?
Adapters are extra layers inserted between existing layers, so they can't be parallelized. LoRA reparametrizes the weight updates and is easily parallelized or merged with the original weights during inference. Also, if you let the rank r be the hidden size you roughly recover finetuning, so you can see LoRA as a generalization of the latter.
Add a task specific layer and only training that layer doesn't work well. In practice, people combine many of these things, e.g., LoRA + task-specific final layer.
Thanks for the clarification. Does that mean then that when parallelization is not important, training an adapter might be just as good as or better than LoRA?
If latency is irrelevant, I don't think there is a strong practical reason to prefer one over another. (LoRA is more elegant in my biased opinion because you roughly recover finetuning with a large r.) In practice, you see one do a little better on some tasks and vice versa on others as observed by papers after mine.
Hi! I in _no way_ mean to detract or malign or "anything negative" the parent comment (communication is hard!!), BUT I really compliment that exact sentence. :)
My background contains signal processing, "pre-deep learning ML", systems engineering, and firmware, and that sentence jumped out at me as crystal clear in my mind, despite not knowing what HuggingFace is or PyTorch.
Correct me if I'm wrong: These huge models involve lots of weights used in large matrices. The contribution of this work is to plug in some matrix factorization and learn a lower dimensional representation, instead of a large second matrix.
Fantastic!
Also makes me wonder what other performance improvements await through proper application of established and well known Mathematics. :D
Great, we can get authoritative answers. (I'm trying to understand the ML space and have mostly done readings, not an expert.)
I am assuming you can have n LoRA fine-tunings, say each specializing in one aspect of a coherent task, with n summers, running in parallel, and then combine them at the end? Or more generally, does LoRA enable a sort of modularizing around a core (un-merged) model?
And curious if you ever tried merging 2 or more fine-tunings and then testing the resultant single model (merge all) against the original tests to check retention?
The gain isn't that significant. We don't understand what these low-rank updates represent, and they might not correspond to "skills" that humans have.
It’s actually completely different. What you linked is about zero shot learning by adjusting the prompt, vs Lora which is about actually fine tuning the weights of the model.
Both LoRA and prompt tuning are parameter-efficient tuning methods. Both of them inject new weights into the model and tune them.
Prompt tuning does so by injecting addition prefix tokens in the input to the model. LoRA does so by injecting low-rank matrices that are additive modifications to a set of linear layers in the model.
They both do something slightly different, but are very much in the same class of methods.
"The other direction, as exemplified by prefix tuning (Li & Liang, 2021), faces a different challenge. We observe that prefix tuning is difficult to optimize and that its performance changes non-monotonically in trainable parameters, confirming similar observations in the original paper. More fundamentally, reserving a part of the sequence length for adaptation necessarily reduces the sequence length available to process a downstream task, which we suspect makes tuning the prompt less performant compared to other methods."
This is key imo: "More fundamentally, reserving a part of the sequence length for adaptation necessarily reduces the sequence length available to process a downstream task".
LoRA conversely has different downsides. LoRA can be used in two ways: merged or unmerged. Unmerged (which is how it's trained) incurs a non-trivial computation cost. Merged means you are modifying the model weights, which means you are stuck with that one model on that device (though, this usually applies for most implementations for the unmerged versions too).
The benefit of prompt and prefix tuning (note: these are two separate methods) is that you can serve different soft-prompts and soft-prefixes efficiently with a single shared set of model weights.
The hit seems to be in energy/cpu not time since the W0 computation is in parallel with the BAx. (My assumption based on the latency claims in paper.) So an issue in edge deployments (battery life, etc.).
> you are stuck with that one model on that device
Upfront I have 0 clue on the actual numbers, but from a purely software architecture pov [in unmerged setup], having that W0 forward process once with n distinct BAx paths (for distinct fine tunings!) would address that, no?
[p.s. say an application that takes as input A/V+Txt, runs that through an Ensemble LoRA (ELoRA™ /g) which each participant contributing its own BAx finetuing processing, sharing the single pre-trained W0.]
> My assumption based on the latency claims in paper.
The latency claims are based on the merged version, where the modifications are merged into the model weights. Hence there is no latency cost, since the final model has the same shape as the original.
> having that W0 forward process once with n distinct BAx paths (for distinct fine tunings!) would address that, no?
The tl;dr is that that works, but is more expensive. Not ridiculously more expensive, but certainly more expensive that processing a few additional tokens with prefix/prompt tuning.
> Merged means you are modifying the model weights, which means you are stuck with that one model on that device (though, this usually applies for most implementations for the unmerged versions too).
If one is careful with floating point issues, it's straightforward to unmerge the weights.
Right, it's mathematically easy (again, up to floating point issues) to recover the weights as needed, but in terms of distribution/serving I'm guessing the plan is to have the original weights and carry around the LoRA weights and merge as necessary.
(Also, I'm assuming you're the first author of LoRA.)
Yes, the plan is to keep the original weights in VRAM and merge/unmerge LoRA weights on the fly. You can even cache a large library of LoRA ckpts in RAM.
You’re assuming a lot more intercompany coordination than would exist. Even though it’s research by Microsoft labs, the researchers themselves are to a large extent autonomous and also narrow experts in their fields.
This process involves low rank approximations -> Lora is a namey sounding term that uses characters from low and rank -> call it LoRA in the paper. That’s all there was to it. Probably didn’t even know the other lora existed.
It’s still a currently-in-use acronym/term that a sufficiently large tech company could conceivably be using both meanings concurrently. This causes confusion and muddies the water of a general web search experience.
Not the same situation, but I remember when “Electron” was called “Atom Shell” because it was built for the (now defunct) text editor by the same name. For the longest time, I had an unsubstantiated thought that it was a new Unix shell that was based around a text editor somehow (yes, dumb). In hindsight, they just had named this cleverly to reference the various layers or shells of electrons orbiting atomic nuclei, thus the eventual name of Electron.
On the other hand, a wireless technology standard is very different than a known mathematical technique that likely predates the wireless meaning anyway.
In all seriousness there should be ML project naming approaches (I should try ChatGPT). Naming a project or a company is very difficult so I can’t blame anyone here.
That said some of these ML project names are especially horrendous (kind of ironic for the current emphasis on generative AI). Transformers? A good chunk of the time I get results about the toys and cartoons from my childhood. Don’t get me wrong, I still think Optimus Prime is cool and the name “transformers” make sense given the function but it’s somehow simultaneously generic AND the name of a decades long multi-billion dollar media franchise…
LoRA is another example, name makes sense but the collision with LoRa is problematic. I, for one, am interested in and have/would apply both. Queue google searches for “Lora radio…” vs “Lora ml…”.
Project naming is hard and I’m just glad to see the activity and releases. BUT project naming is essentially a base usability condition and should be considered as such: just like creating a README, getting started, providing code examples, etc.
It reminds me of trademarks: if you’re looking for trademark protection it won’t be issued if it is overly generic or likely to “cause confusion in the marketplace” with an existing trademark (basically same or similar name in a somewhat similar/adjacent field) - you can even reuse names but only if it’s obvious to people from basic context that they refer to different things. I’m not a trademark attorney but I think LoRa vs LoRA would get refused because it’s “computer stuff”, while a shampoo named Lora would be fine (as an example). If you’re curious there are official categories/areas from the USPTO that break these down.
Both of these examples wouldn’t have a chance at trademark protection. Note I’m not saying they should have trademark protection, just that it’s an example of a reasonable standard that should be considered/compared to for good open source project naming.
Good question! I came up with the name because the idea is best described as low-rank adaptation. I know very little about radio communication and didn't anticipate the visibility my repo has today :)
Came across this library in the past where you can easily add LoRA and other efficient fine tuning techniques easily into huggingface models. Haven't tried it though and support for different models may be limited
I’m wondering what the difference is between LoRA and adapters. Especially I’m wondering whether LoRA is being used for LLaMA because it is proven to be better or simply because it happened to be the first such technique that worked and now everyone just uses it. In other words: Is it worth it trying the adapter approach with models like LLaMA?
The difference is that this inserts adapter layers on top of the model. In contrast, LoRA decomposes the model weight matrices using low-rank decomposition. So, LoRA increases finetuning performance by reducing parameter numbers whereas Adapters increases efficiency by keeping the pretrained model frozen (and only tunes a small number of parameters added to the model).
I really hope this doesn't displace regular fine tuning techniques. Dreambooth is superior in quality to Lora with image generation, and I suspect that it's similar with LLMs.
I suspect it’s not that similar. The intuition behind LoRA is more true the higher the rank of the weights of the model. Even the smallest LLMs have considerably higher rank weights than Stable Diffusion. They are large, after all.
The LoRA paper’s ‘problem statement’ makes a compelling case for practical benefits of the approach. Specifically, no added latency, no serial processing bottlenecks, shared baseline model, compact time/space requirements. How does dreambooth stack up in this regard?
In the image space, dreambooth full-model tunes can handle multiple concepts and tend to be easier to get hard/complex things like a person’s likeness correct. I’ve found that LoRA tunes struggle to be accepted by people as producing their own face compared to full dreambooth models tuned on the same inputs, most likely because we are very sensitive to facial differences of faces we are very familiar with. I haven’t seen this effect for styles or other kinds of concepts, where people are a little less sensitive about the fidelity. LoRA is much easier to train, easier to compose, and can have the base model swapped out in many cases though so if it’s good enough for the concept you are trying to add to the model it’s often worth the subtle quality loss.
“Aghajanyan et al. (2020) shows that the pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace.”
Would be great to have an informed practitioner comment (sota) on why we opt for random projection. Is the actual ‘intrinsic’ vector space uncomputable? Too slow to find?
> The core idea behind random projection is given in the Johnson-Lindenstrauss lemma, which states that if points in a vector space are of sufficiently high dimension, then they may be projected into a suitable lower-dimensional space in a way which approximately preserves the distances between the points.
> Is the actual ‘intrinsic’ vector space uncomputable? Too slow to find?
OMG yes. It's also an unsolved problem, once can approximate it. I've written several non-parametric blind arbitrary dimension DR algorithms and been obsessed with the space most of my life. If you think O(n^2) feels slow, try O(n^3)...:) For more, read about mean shift clustering, or the new hot stuff: topological data analysis/bar codes/mapper algorithm.
Random projects work well in high dimensional spaces, they’re cheap, easy, and require no understanding of the initial space. Part of the point of Lora is efficiency, after all!
Has anyone diaried out a good learning path for going from a larger pre-trained model to a fine tuned model? Trying to understand all of the parts here but it sort of hard to fine anything linear...
Btw, it's kinda crazy how bad the GPT4-J results in the blog are compared to the Dolly one, which seem pretty good. Do we know why it works so well to use this 50k dataset?
Dolly is instruction fine tuned whereas GPT4-J is not. Which means that it doesn't even understand that it is being instructed to do something, it is just doing an autocomplete.
or on macOS, although I'm not sure it's still by default using case sensitive file system or not. I do remember the first time that bit me though, being a programmer using Linux collaborating with a developer using macOS. Must have been in ~2005 or something.
The one which bit me happened when I was running a java minimizer / obfuscator on a Windows platform and it assumed that A.class was not the same as a.class. It worked great on Linux and didn't warn that it had overwritten a file, resulting in a package which almost worked.
> Unlikely that they even consider checking whether they are stomping across existing names.
Or it's on purpose as existing terms already have good amount of search traffic for those terms, and Microsoft know Google/Bing will rank Microsoft's own pages higher than what's already out there.
{kind=link}
I believe there will soon be a cottage industry of providing application-specific fine-tuned models like this, that can run in e.g. AWS very inexpensively. The barrier today seems to be that the base model (here, Meta's LLaMA) is encumbered and can't be used commercially. Someone will soon, I'm confident, release e.g. an MIT-licensed equivalent and we'll all be off to the races.
[0] https://github.com/tloen/alpaca-lora
[1] https://crfm.stanford.edu/2023/03/13/alpaca.html