Hey HN community -
I’m Ivan from Datasaur (https://datasaur.ai/) - we build software to allow humans to more efficiently label data for training natural language processing (NLP).
NLP algorithms are being trained in a wide variety of industries - from customer service to legal contracts, forum moderation to restaurant reviews. All these algorithms benefit from recent breakthroughs in academia and a generous open-source community. However, in order to be deployed to the real world, they require a custom set of training data to learn and understand the language unique to each industry. Therefore, people around the world are meticulously labeling data samples.
Example sentence: London is the capital and largest city of England and of the United Kingdom.
Labels: “London” —> “capital”, “United Kingdom”
Labels: “London” —> “largest city”, “England”
In the last few years I’ve worked at companies such as Apple and Yahoo and noticed that many organizations tend to reinvent the wheel when creating labeling interfaces for their labelers. Some companies still do this work in Excel.
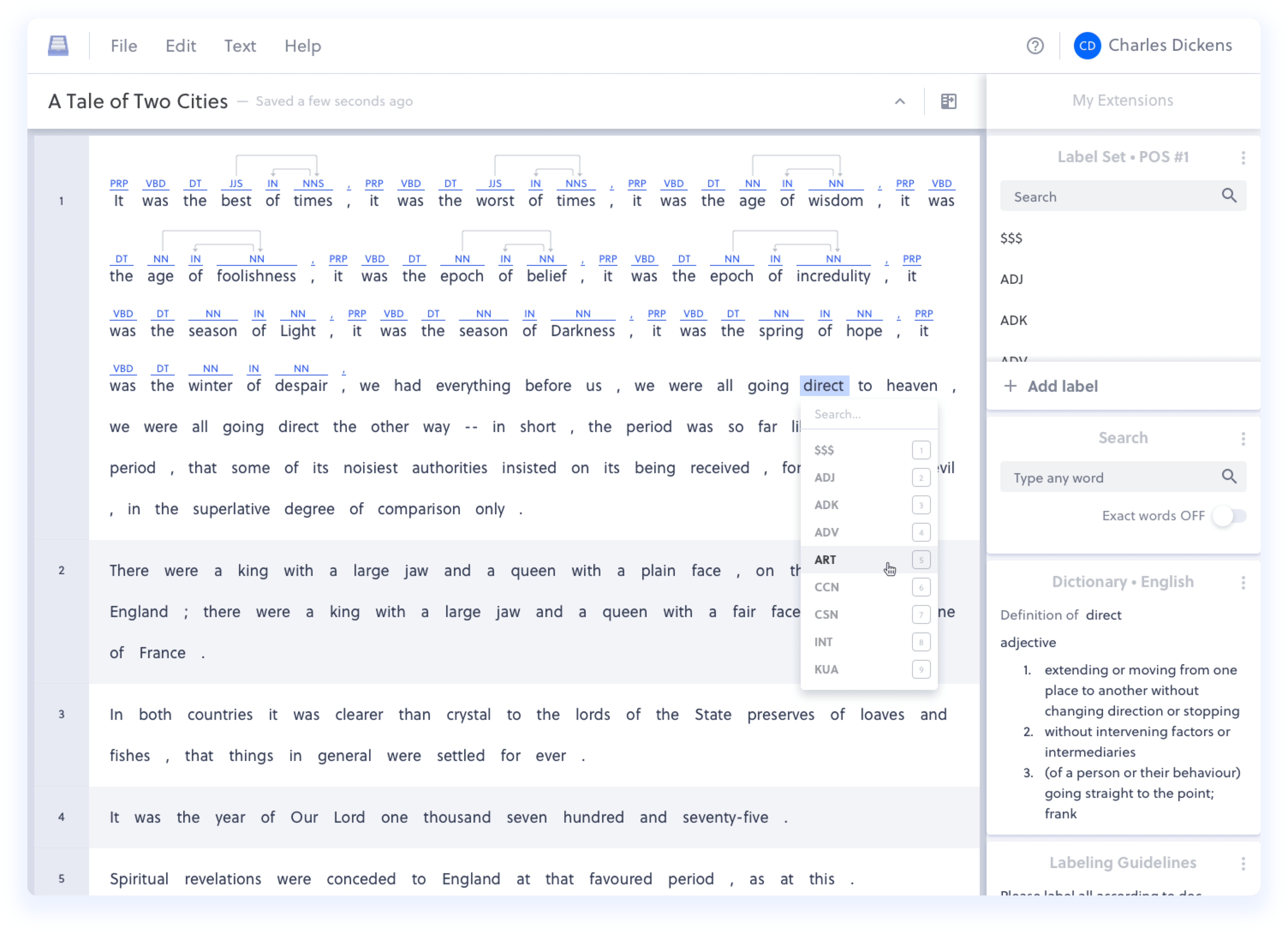
We saw an opportunity to create a "single interface to rule them all" - to handle all sorts of text labeling tasks.
We leverage existing NLP capabilities to intelligently validate the quality of labels in a document and complement human judgment. Furthermore, we already understand terms like “Starbucks” and “New York” - why spend time labeling these terms from scratch every time? We created an API so you can plug in existing models to apply a first pass on labeling the document. We also built many other extensions to help labelers optimize their time - a “find and label” extension for labeling repetitive terms, a dictionary extension for quickly looking up unfamiliar terms. We spent the past year building out the labeling solution I wish I could have used.
We now handle named entity recognition, parts of speech, document labeling, coreference resolution (multiple words referring to the same object/person) and dependency parsing (drawing relationships between words). A case study with one of our clients shows 70% improved labeling efficiency upon adopting the Datasaur platform, and we have much more room to improve.
We also spoken with 100+ AI teams globally and identified the best practices in labeling. In addition to providing an enhanced interface, we can help track labeler performance, peer disagreement scores, and detect/remove labeler bias. By incorporating and encoding these features into our software, we can not only help improve the labeling efficiency but also improve the quality of the data and therefore the resulting AI model.
We believe that as AI becomes ever more prevalent and ubiquitous, labeling will become an increasingly important task. AI is a garbage-in, garbage-out technology, and the quantity and quality of data can often make a critical difference in the resulting AI model. We’re really excited to open Datasaur up to the world today and hear your feedback. Have you run into similar labeling issues? What tips and tricks have you employed to keep up with AI’s voracious appetite for data? We’d love to hear how you’ve tackled data labeling at your own companies. Thanks so much in advance!
Ivan
{kind=link}
It doesn't include a ML assistant though.
We have built a semi-automated annotation tool for our internal use too. ML models help classify documents and extract named entities by making suggestions. Sometimes I'm thinking of spinning it off as a standalone product but not sure how big the market would be.