Not every workload is memory bandwidth bound like his "make -j16" compile. Some workloads need memory latency or fast inter-core (and inter-socket) operations (e.g. RDBMS OLTP), some need CPU throughput (e.g. HPC), some need best possible single thread CPU performance (e.g. some gaming).
As he wrote, CPUs are most efficient (compute per Watt) at a specific frequency, and if his CPU mostly waits for RAM, this can be done at low power.
It's probably possible to create x86-64 CPUs with narrower backends (fewer execution units) with microcode-emulated 128 and 256 bit registers/operations (and maybe even emulated FPU) and get a cheaper and faster build server, if it was economical to fab such narrow-use-case chips (those would be good for redis/memcached too I imagine).
> Not every workload is memory bandwidth bound like his "make -j16" compile.
He actually did `make -j32`, not 16. Which is going to absolutely devastate the cache.
`make -j<number of cores x 2>` was a good rule of thumb back when you had 1/2/4 physical CPUs with their own sockets on a motherboard and spinning rust hard disks. A lot of "compilation" time was reading the source code off the disk. But it doesn't make any sense anymore with so many cores, hyperthreading, and SSDs that serve you the file in milliseconds.
If he's bandwidth limited, he would gain a significant performance improvement by reducing the number of processes.
I'd reserve judgement until I saw measurements. Maybe all 32 jobs are using the same cpp/gcc/asm/ld binaries (or whatever the stack is these days) which never get evicted. And I presume this is running under DragonFly BSD whose design goals include aggressive SMP support, so things might be different there. I don't know.
It is definitely not "microcoded" - 256-bit operations are just sent in halves to the 128-bit ALUs and combined for the final answer.
Don't get mixed up between "microcoding" and "micro-op" - the latter is something different, slower and which usually requires some kind of transition in the decoders and uop caches to start reading microcoded ops. The latter is the "normal" or "fast" mode for the CPU and just because one instruction turns into two uops (or macro-ops or whatever AMD calls them) doens't mean microcoded.
You do want it to out-of-order and branch predict and speculate enough to issue speculative RAM reads as soon as a possibly needed address is available, to hide RAM latency (as long as rollbacks of speculatively executed operations hide the loaded values in the cache so the speculation leaves no side effects), that is important for performance.
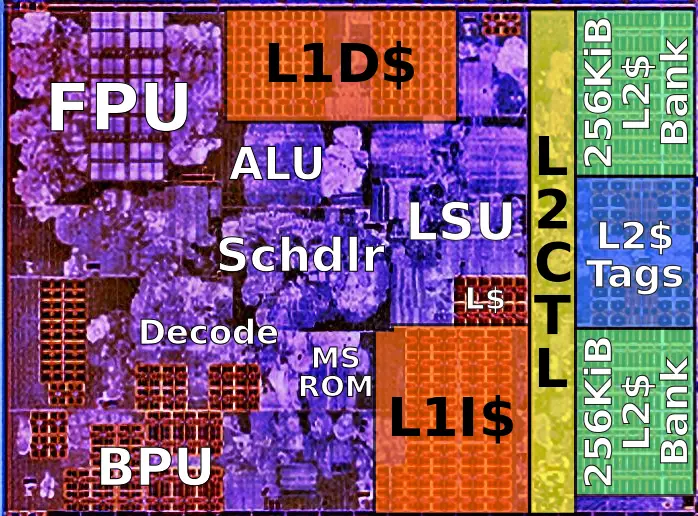
In that picture (thanks!) I see the FPU is big, the decoder is big, the branch predictor is big, the rest is probably needed. Maybe emulated FPU is good for some workloads, maybe ability to program in microinstructions instead of x86-64 is useful too. But maybe silicon area is not the expensive thing (dark silicon, etc.).
This is responsible for Ryzen losing to Intel in SIMD heavy benchmarks. The upside is that it avoids the reduced turbo boost Intel does for some 256-bit AVX instructions (and even worse downclocks caused by AVX 512), so for workloads mixing avx and normal instructions it shouldn't do too badly.
Is there a good resource that explains the difference between those ("decode" vs. "trapping") on a modern CPU? When I see "trap" I imagine the kernel catching illegal instruction exceptions and emulating them in software, but it doesn't seem like that's what you mean?
Modern CPUs execute micro ops, RISC-like instructions (e.g. load from memory address to register, add two registers, store from register to memory address). The CPU's "decode" stage translates x86 instructions into micro-ops (often 1-to-1, but x86 compare followed by x86 jump are translated into a single micro-op, while some x86 instructions are translated into multiple micro-ops).
On one CPU model a x86 operation like "256bit add" might translate into "256bit add" micro-op, and on another model the same x86 operation might be translated into a series of micro-ops like "128bit add, wait a cycle for the 1st add to finish, pass the carry bit into a 2nd 128 bit add", because that model doesn't have a real 256bit adder. So the latency of the operation is 2 cycles, but nothing else is changed.
Some x86 instructions might be very complicated and cannot be translated into a fixed-length series of micro-ops using a template. For example, the integer division, square root or the string compare machine instructions might be loops with conditionals in them and don't run the same amount of micro-ops every time. They can be implemented by Intel using a program written in micro-ops. Intel stores this program in flash on the CPU and the decoder knows to run that program when encountering the instruction. The OS doesn't need to help here, this is not emulation or software-floating point, it's just that the single instruction takes 200 clock cycles. What this does to the out-of-order engine is another story. These "programs", called microcode, can have bugs and newer versions of microcode updates, sent to the CPU at boot by the BIOS/UEFI and/or by the OS, update them.
I'm interested in performance optimization (especially under linux) and its intersection with computer architecture. Would you mind recommending me any resources to get started there?
Stilt is a magician in getting peak performance per watt out of everything. Down to tweaking individual straps for memory timing on binary firmwares for amd graphics cards.
3.6 @65W is impressive, almost stock speed at nearly half tdp.
Basically a 10% performance penalty for a 45% power savings. And you might not even see that 10% performance penalty if you're machine is bottlenecked on memory/storage.
Calling this "Unexpected" seems like a bit of a stretch. In particular this part:
> Of course, in the server space, we've known for a long time that maximum
efficiency occurs with a high number of cores running at lower frequencies,
and that efficiency trumps performance on machines with high core counts.
But I never considered that the consumer Ryzen CPUs could also benefit from
the same thing until now.
makes no sense. This principal applies to all CPUs from the smallest SoCs to the largest server CPUs, why on Earth would you not expect it to apply to desktop CPUs?
You could do the same thing with a 6 core i7 and 2133 memory. Intel CPUs have long supported an adjustable power limit to constrain operating frequency based on power consumption just like he describes for Ryzen.
You are confusing principle with implementation. Reducing clock speed reduces power usage and you can compensate with more cores is indeed a truth. However, finding that option in consumer hardware has been relatively difficult. That is the surprise indicated.
Ryzen is known to be memory constrained even with much faster memory than he used. It is completely predicable that he found his CPU to be severely starved for memory bandwidth thus enabling him to reduce operating frequency without penalty.
This is like putting an LS engine in an otherwise stock Miata and acting surprised that you can run the engine at lower RPM and still put in good lap times.
Are you kidding me? That's only true if the constraint can be removed in a hardware upgrade. Apparently latter day Xeons are not much better at hiding memory latencies than Zen and no longer outrun it as much like they did Bulldozer on other operations which made the latencies irrelevant.
In other words, he's reached peak CPU. As in a faster unit will not speed it up, and more cores can only do that to a point. Amdahl law (power efficiency variant) and also memory controllers say hello.
Note that the author is not claiming that he compensated with more cores. He is claiming that the performance is roughly the same, at the same core count (8), regardless of frequency.
Well I suppose the part that might not apply to desktop parts is "efficiency trumps performance". Many desktop uses don't care about efficiency, but care about performance.
For servers, the purchasing decisions are probably much more quantitative, and if you are buying a high core count machine it probably means you have a parallelizable workload, so no efficiency comes into play since you have a lot of choice on the frequency/core-count spectrum, versus power, money, space, etc.
More specifically, the interprocessor interconnect (infinity fabric) system ryzen uses is tied to the RAM clock. Ryzen clumps there processosor in groups of 4, and uses infinity fabric as an interconnect between those; so I am not sure you will an effect larger then Intel on a quadcore ryzen.
I think the claim that parallel compilation with gcc is memory bandwidth bound is unlikely. gcc is known to be a very pointer-chasy, branch-mispredicty load that is highly sensitive to memory latency - far from a streaming load that is sensitive to raw bandwidth.
Still, the conclusion holds: if most of the time is spent waiting for values to come back from memory, a higher core frequency has strongly diminishing returns.
That's only true if you only compile a single file at once which is an exceedingly rare use case for a build server. As soon as you compile files in parallel the CPU can simply switch to the next hardware thread during a memory load from main memory. Then there is the fact that dual channel DDR4 just doesn't provide a lot of memory bandwidth in the first place. A 16 core/32 thread desktop CPU is probably not going to happen on the AM4/Ryzen platform even if everything suddenly supports multi-threading on 16 cores simply because the memory bandwidth isn't enough to translate into meaningful performance increases. GPUs have horrendous memory latencies but they perform well precisely because they can just switch to the next thread and execute that one while waiting.
Well you are mixing the effect of "more cores" and SMT together here. Sure, SMT helps hide some latency effects, but it doesn't significantly increase the demand for bandwidth. The increased bandwidth requirements when introducing SMT are probably approximately modeled by the increase in performance: so a 30% uplift from running two hardware threads per core means that bandwidth requirement increases by about 30%.
That's not enough to turn gcc from a largely latency bound load to a memory bandwidth hog!
Ryzen only has two threads per core, so one would be able to see at most a 2x gain. That's not insignificant, but still far from what one needs to start seeing bandwidth problems.
Unless the AMD design is unusual it is not very close to zero return: a significant part of the "path to memory" involves things run at the core clock, in particular everything from the core to the L2 and probably some part of the coordination logic which communicates with the "uncore". I'm not sure about AMD chips, but on some chips there is a relationship between the uncore speed and the core speed: e.g., the uncore speed might often be the same as the maximum core speed for any core on the socket.
Adding to that, there are other effects that allow core frequency to leak into the performance of memory-bound programs, such as a higher frequency allowing the core run ahead more quickly to get more memory requests in flight, recover more quickly after a branch misprediction, etc. Try it sometime: find something which is really memory bound and crank the frequency way down: there will probably be a significant effect, but not nearly in proportion to the frequency difference.
Short form and generalized: when one subsystem of a larger system is not your bottleneck, it's often possible to lower the resources for that part of the system without impacting overall performance.
Here's the same author from pretty recently comparing the 2990WX to some Xeons (he says E5-2620 but doesn't mention which version — could be anything from Sandybridge to Broadwell):
{kind=link}
As he wrote, CPUs are most efficient (compute per Watt) at a specific frequency, and if his CPU mostly waits for RAM, this can be done at low power.
It's probably possible to create x86-64 CPUs with narrower backends (fewer execution units) with microcode-emulated 128 and 256 bit registers/operations (and maybe even emulated FPU) and get a cheaper and faster build server, if it was economical to fab such narrow-use-case chips (those would be good for redis/memcached too I imagine).