The \1 is from the original puzzle, and refers to the value of the first (capture group). I ran into this issue while filling out the puzzle. The \1 is required to 'propagate' the value in that square to other places. The puzzle is ambiguous without this fix.
Thanks for the pointer, I've added the note in the comments. Hopefully the puzzle is editable.
Brilliant. My dad is 71, loves puzzles (like cryptic crosswords and Sudoku), is a huge technophobe, and has just retired. This should keep him busy until about 2022.
Technophobe. Just acquiring the necessary Google skills to find out what the proper regex rules are will probably take him till Christmas. But hey, the man loves a challenge.
I will always keep a Windows install at the ready just for RegexBuddy. I use it mostly to take a regex and generate the code I need for it (e.g. find the first numbered group in match in javascript), without having to remember language specific details.
I think parent said why: there's no RegexBuddy on Linux. I can see you're new, so I won't be harsh but HN isn't the place for this kind of commentary. Everyone here understands the difference between Windows and Linux. Judging and/or trolling over Windows is boring, take it over to Reddit or something.
Yes, thank you. I of course use Linux, but I really don't care to remember the specifics of regex libraries across PHP, Python, JS or Java. So I just work out my regex, and from the drop downs choose "Use->Javascript->Chrome->Get Text From Numbered Group". And it spits out like 6 lines of JS that will handle cases of it either being found or not. You can choose the names of the ingoing and outgoing variables.
You don't always get to pick the flavor of regex engine you're using and I've sort of become (partly because of RegexBuddy) the "regex expert" at the office. Aside from `re` in Python I don't even remember the names of the regex libraries. Why should I?
The funny part (to me) is that it was already obvious you use Linux or mac -- some flavor of (star)nix -- because you said you keep a Windows install at the ready. That implies to me that Windows isn't your primary OS. I keep a Windows install at the ready too, for a whole bunch of reasons that have nothing to do with how much I like or dislike Windows.
I would love to be able to remember regex specifics from lib to lib and app to app, but try as I might, I can't. I never know if I have lookaheads or backrefs or named captures available and what the syntax is, I can't remember if there are named character classes. I end up reading the docs, again, almost every time I dig into a regex problem. Same reason for me- I use too many flavors of regex libs. If I could stick to one language, I'd have some hope.
I haven't tried RegexBuddy, but now I'm going to because of your comment, thanks for sharing!
I highly recommend it if you have to deal with regex a lot. I really wish it was open-source, or there was some OSS alternative as good as it, but oh well. The tools linked above are great for simpler usage.
The built in regex step-debugger is also great, though I've learned that if I have to rely on that, it's probably not a task well suited to regex.
I'm sorry you feel that way, that sounds like maybe you've had some bad experiences here and are turning pessimistic about HN. Just because it happens doesn't mean it's universally accepted. Personally I would say exactly the same thing in response to the above comment if it was talking about Linux instead of windows and had nothing substantive to support it. Yes, you can find people who agree with any insults you want to throw out, but how about we try to be the good guys instead?
Find some awesomeness here on HN -- there's a lot of that too -- and comment about it. Build something and show it off or support someone else who's built something cool. Write comments that contribute meaningfully and are positive and you will find more upvotes than you can possibly imagine, if upvotes are what you're going for. And you're right, you can find lots of upvotes (and downvotes too) by judging other people's legitimate choices without even bothering to understand them, but that doesn't make HN a better place, it doesn't help anyone learn, and it might not make you happy in the long run either, even if it's fun for you at the time.
We get to decide if this place is cool and supportive and fun to play in, or lame and thorny and dangerous to share any of your thoughts for fear someone will be an ass about it and insult your choice of tools. I choose the former, and I'm happy to spread the love and request that people refrain from trying to knock others down or engage in flame wars.
I generally upvote people who reply to me just as a way to say thanks for reading what I wrote and engaging with me. Here's one for you. I hope you'll find more peace on HN and get exposure to more of the positive side of it. There are some incredibly amazing people here, and it's true there are also some destructive forces too. I hope you can let the crap roll off and seek out more of the good stuff!
This pipe dream is what drew me to HN ten years ago. And while there are specifically rules against drawing comparisons between HN and reddit, years ago, the parallel made sense. These days, being totally honest, I find reddit to be more approachable and friendly and informative in the types of subreddits I read than HN, the vast majority of times. The reason I keep coming back to HN is for the once-in-a-blue-moon comments which blow your mind. If those comments stopped happening, or if they started happening on reddit, I'd never come back. There is absolutely a creed which is the centerline of HN, and deviation from it -- even totally reasonable, level-headed deviation -- is often punished with downvotes into invisibility. I've specifically created a Chrome browser extension to remove all point/color information from post comments -- and recently uploaded it to Github [0] -- just to keep my own voting habits from being influenced by this brutal kraken of sameness that exists on HN. My post above is a little bit tongue-in-cheek, but in my experience, one of the subjects you can most find downvotes with is the classic win/*nix flamewar. Even something totally reasonable and said in a straightforward, matter-of-fact way which promotes something about Linux in a thread about Windows is annihilated. Unwanted facts and differing viewpoints are erased from existence. That's HN, even if there's some silver lining in there occasionally.
Really? I use it fairly often, usually for cleaning input data and similar. But I only use a subset of regex functionalities that works across different engines and that doesn't make problems with escaping strings (no backslashes and similar).
As I get more experienced in operations, I find regex to be more and more invaluable. I used to dread doing a regex, now I get enjoyment out of sorting out a tricky one.
I've worked on the project where some XSD files defined fields with regex restrictions, also some rules over fields added other stricter regexps or negative regexps depending on some context in a format called Schematron. I had to generate XML files conforming to those XSD, so I used some tools around Z3 solver and Microsoft.Automata to generate those strings conforming to multiple regexps. It would convert the regexps to finite automaton and intersecting them, walking it from the starting state to a final one over a charset.
I am toying the idea of writing a little game where player A thinks of a regular expression, and player B tries to guess. If B guesses right, they win. If B guesses wrong, A has to provide a false positive and a false negative (if they exist), and B gets to guess again.
Can you think of ways to automate the roles of A and/or B?
Thanks. I had figured out that grammar induction was the right word to look for a while ago. (But took me a bit to find it.) I know the paper you linked to, but yes, it's not quite the right setup.
With a fixed guesser, that would encode all regular expressions / finite automata as sequences of binary digits. (But in a interestingly different way from just serializing the table for a DFA, or writing down the regular expression in ASCII characters.)
Automation of regular expression generation, it seems easy : use RE fragments and aggregate them, or walk the type hierarchy of the RE AST and generate them randomly.
B needs to guess A's RE so we need to generate examples of strings belonging to it to gives hints :
this is exactly the use case of AutomataDotNet.
Also if B guess a RE that is equivalent to A's RE it seems unfair to not attribute a win, so we need to tell if 2 RE belong to the same equivalence class. AutomataDotNet does have a AreEquivalent method.
You can automate the generation of false positive and a false negative with the method Minus to creates an automaton that accepts A-B or B-A and generate an example.
You are right about the equivalence classes: for that you want to talk about the corresponding DFA (which have a unique normal form in the shape of the minimum DFA).
I am not sure about the rest of what you are saying: in general even just minimizing regular expressions is EXP-SPACE complete, if I remember right.
Yes, generation of false negative and false positive ain't so hard---theory agrees with you. But automating the guesser is, as far as I know.
I was talking about generating hints to give an opportunity to the RE guesser to find the secret RE. You seem to talk about automating the RE generation based on the pattern of the hints, yeah I didn't thought about that, the other answer seem to talk about it.
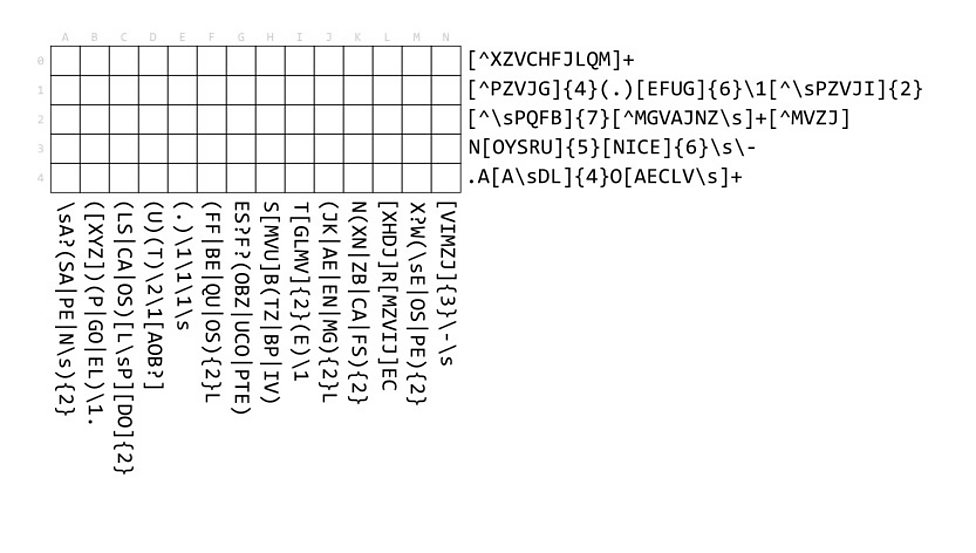
Well done. I don't know what you think but I found that most of the time the character classes would intersect perfectly (i.e. there'd only be one character possible once you intersect both sides of a single square). That made it pretty easy overall since for the vast majority of the board you don't have to worry about the "context".
But I guess if it's meant for an audience of folks not very familiar with regexes it's difficult enough as it is.
Well, thanks. I tried to cheat with https://github.com/blukat29/regex-crossword-solver and got hit with lex parsing errors! My limited python and 5 minute effort resulted in failure!
At least I got to read the message though :-)
Assuming 0 indexing: row 0 column 4. Constrained by rows 0, 2, 3 where rows 0 and 2 have [^XZVCHFJLQM] and [^\sPQFB] and row 3 has [OYSRU]. All of: O, Y, S, R and U match. Am I missing something?
Interstingly, Bletchly Park is known to have used crossword puzzles published in The Daily Telegraph as a recruitment tool for "codebreakers" during WWII.
Note that as a Mystery Hunt puzzle, the goal of the puzzle isn't just to fill in the grid, it's to find the answer, a secret word or phrase that would be filled into another puzzle (the metapuzzle).
The puzzles generally don't tell you how to extract the answer, but the idea is you know it when you see it.
I also created an HTML-based version of this one some time ago that allows rotation and color codes the rows as matching or not:
https://gregable.com/p/regexp-puzzle.html
I know that there are problems to do with regex matching that are NP-hard. So I'm wondering if it is possible to attack this puzzle using an algorithm that simplifies the individual regexes using knowledge of the regexes that that they interact with?
This problem is NP-hard by reduction from SAT. Treat each column as a truth variable and use the rows to encode CNF clauses. For example, `(A | ^C)` becomes `(1..)|(..0)`. Then set all the column regexes to `( 0* )|( 1* )` to enforce a consistent truth value for each variable.
A variable becomes '1' in the corresponding position and '.' everywhere else, and similarly with negations of variables and '0'. The regex is then just an alternation of these sub-regexes. This incurs just a linear blow-up in the number of variables, for the '.'s.
You could expand each regex to a regex on the whole table, and then take the intersection of the corresponding NFA/DFAs. Unfortunately, I suspect this takes exponential (or worse?) time in the worst case.
You can solve it using a SAT solver like Z3. There are particularly elegant solutions in Haskell that basically interpret the regex but on "symbolic" characters rather than real ones. You can then ask what values these characters can take such that all regexes match.
It certainly should be. There limited things in the puzzle help as well.
For example, you can split each one of these regexes up into smaller ones based on positioning. Now some of them are simply "match any of the following characters" which can be combined together with set intersections (and something similar with "none of these characters).
That wasn't as hard as I thought it would be. I was worried that, without stard/end of string anchors, things could get quite hairy, but the biggest stretch of logic was just, "There are five spaces for me to fit a character, an optional characters and two two-character sequences. Therefore that optional character must not appear."
Does any common regex format/dialect require '\-' for a literal hyphen? AFAIK it's only special inside character classes, and escaping it doesn't necessarily work there if it would form a valid range identifier.
I don't know of any that require it. But it's common to see punctuation characters escaped like that because Perl (and PCRE and its various cousins/descendants) allows you to escape any non-meta-character and have it treated as a literal.
I suppose the two main benefits are
(a) neither the writer nor the reader has to remember which punctuation characters are meta-characters (you just have to remember that it's always a literal if it's escaped), and
(b) in implementations like PHP's which try to replicate the Perl-style 'delimited' syntax (e.g., /foo/), it prevents characters in the pattern from conflicting with the delimiters.
Maybe there's some other advantage but i can't think of what.
It is indeed machine-solvable; I wrote a solver for regexcrossword.com puzzles a while back (https://github.com/hermanschaaf/regex-crossword-solver). It was great fun, maybe even more than solving the puzzles by hand!
Nice! At Keplers in Mountain View you can buy version of Scrabble that uses regexes. The designer used to sell it in front of the shop -- he is obviously a programmer.
It wasn't a short-term item, but poor Kepler's has shrunk so much who knows if it's in stock or not. I would call them. It wasn't described as using regexes of course, so you'll have to say something like that special version of scrabble.
The designer is local so if they no longer stock it you could look online...but it's better to get it from the shop if you can.
Never played it, but from looking at the box of talking to the inventor it was just that The set of letters included regex operators and those The set of letters included regex operators and those you could put on the board as well. Meaning other people could use him as well To make words.
{kind=link}
{kind=link}
{kind=link}