I saw a lot of "should we use Cloud, no its crazy a GPU only costs $X". The key is that if you believe GPUs are going to get updated every year, and/or the best thing for ML may change (see TPU and plenty of startups with custom hardware) then suddenly buying hardware for 24? 36? months isn't as obvious.
We (and AWS and Microsoft) have K80s because Maxwell wasn't a sufficiently friendly all around part. We're all going to offer Pascal P100s and in the future V100s. The challenge for buying your own is that P100s are available now-ish and V100s may be available in less than 12 months.
Buying a P100 or similar part today doesn't mean it won't still be working in a year, but it will suddenly mean you've bought a part that now has much worse !/$ in just N months. If you have an accounting team that is spreading your $Xk over those 36 months, the reality is that you have two options: tell everyone they have to make use the old parts ("we're not buying new GPUs until it's been 36 months!") or realize you're going to get a lot less use out of them.
To be clear, the progress in this space is really impressive. And the same problem above applies to us (the cloud providers). Despite my obvious bias, if I were fired today, I'd be renting to do deep learning just based on the roadmap alone (not to mention the ability to suddenly spin up and down).
Again, Disclosure: I work on Google Cloud and want to sell you things that train ML models :).
Except buying hardware isn't a 24-36 month investment, you could buy new hardware every 3 months or so and it would still be cheaper than renting. Renting only makes sense when you need to scale horizontally, but for most people's use cases having an in-house machine is sufficient.
The problem is that a month of GPU time on a cluster can buy you the hardware itself. If you are doing serious deep learning work it's just not cost effective at this point. If the costs come down by half or more, it may start looking viable for people who need a lot of resources.
Can you explain your math? A K80 on GCE is $.7/hr x 730 => $511/month if you were really 24x7. A K80 (and really we sell them by the die not the board) is more than $1000.
I don't disagree that a consumer board is about that price, but they're not apples to apples. (Either in memory size, reliability or both). I'm fine with that being the real complaint: (major) cloud providers only sell the Tesla class boards, and they're really expensive ;).
It would be nice to see Nvidia or someone expand on this, so that users who have to make this choice can do so without guessing. If Google or AWS or M$ could publish reliability information, that'd be cool too.
Illustrative case: I run Monte Carlo work on GPUs and administer a local compute cluster. I tested a workload on a 16 GB P100 and a GTX 1080. A 12 GB P100 costs (academic, EU) 5000 euros while the latter costs 700 euros, but the performance difference is about 2x. Still, when we ask Nvidia reps, they say not to bother installing GTX cards in our cluster, because they aren't designed for 24/7 work, not commercializable etc. Even so, the GTX would have to burn out 3 times before the choice of P100 breaks even. Burning out three times means GTX 1080, then 1180, 1280 etc.
A GTX 1080 is like $550 at this point, K80 cannot really compete with the cost effectiveness here. And it is probably not going out of fashion in one year, so the price is totally worth it.
The real attractiveness for cloud at this point is if you are going to train your model with 8-GPU or more, that is likely not feasible for individual enthusiasts, but demand for such machine is rare for hobbyists anyway.
This is kind of the key. If P100s were common on gce, it would be a better comparison. But the k80 is very old by today's standards, and a consumer card will run circles around it.
They say they used four Titan X cards for a month. I was actually looking at google cloud machine learning since I thought being targeted to tensorflow would be the most cost effective. But it's 0.49/hour per ML training unit, or 1.47/hour per GPU. A basic gpu gives 3 training units, so I thought that something approximately similar would require 12 training units, which comes to something like $4000+ a month. Maybe I completely misunderstood the resources being offered though, because you are right that cloud engine costs seem much lower.
I'll have to revisit the math here, though it worries me that it's not at all clear that a K80 will be much faster than a Titan X for a given problem. E.g. https://www.amax.com/blog/?p=907. It would also be really nice to get some pricing and benchmarks for the new TPUs, assuming they are priced better.
Maybe part of the problem is that vendors are not making it remotely easy to even understand what performance you'll actually get for a given price.
The comparison should be between a machine off-premises with as many GPUs in it of the same type that you intend to use and power + cooling.
Payback time according to my own calculations depending on GPU model and machine used compared to the various cloud offerings is between 4 and 6 months when used continuously.
Isn't there an abstraction cost though, since that price is only for half a board? In my experience (with AWS) I've had a machine with a Titan X outrun a cloud instance by 1.5-2x, which is significant.
There are also other hidden costs that aren't factored into that number. I'm having a hard time getting anything reasonable for under $750/month for 24/7 usage: https://cloud.google.com/products/calculator
Disclosure: My incentives compete with google cloud. We have had enormous cost savings with on premise customers.
I think one thing that isn't being said here is: Most enterprise customers can't actually leverage that much GPU capacity anyways. We have found incremental addition of GPUs to hadoop clusters (yes this is a thing) to be great.
It's cheaper, allows gradual adoption of deep learning and is a familiar toolset for folks already doing some sort of machine learning.
I won't comment on research (not our domain). Depreciation on hardware is pretty standard - that being said it also comes with established SKUs from dell,hp,cisco,.. with proper support.
Analytics clusters (while hard to manage) are fairly robust already to job failures. The cost savings just makes a ton more sense when you are doing continuous workloads for different use cases.
While it's easy enough to add GPUs to a Hadoop/Spark cluster (and we did so too via Dataproc [1]) are you just saying that means you assume closer to 100% utilization due to sharing?
If so, that's fine-ish, but then people have to wait (you're either full and people are waiting or you're at less than 100%). My preference is to run for XX minutes per job on-demand (per person). If you have tons of non-overlapping users, you can absolutely aggregate them. But how many do you buy and how quickly do you upgrade to newer hardware?
I'm talking about on prem clusters where people aren't using cloud. Many of these are just managed by central IT depts (eg: most of enterprise) . We've found folks are perfectly happy to add gpu nodes to an existing cluster managed by yarn or mesos. The incremental upgrade with just another SKU with an existing hardware vendor purchasing/procurement already works with is usually enough.
That being said - it can usually be every 6 months with a renewal of every 2 years or so. Your hardware timelines aren't far off. That being said - I was getting that upgrade cycles don't matter as much.
GPU clusters are enough of a new thing for enterprise yet that the jobs being run aren't even that high spec yet.
My opinion nothing more not claiming this is fact: Google has marched so far ahead of the rest of the world they aren't really paying attention to where current clusters and usage are. It seems a lot of the cloud usage is oriented towards startups and researchers (which isn't a bad thing, most folks in DL are researchers).
For enterprise, they might offload some workloads. There are definitely some workloads where cloud resources (spin up and shut down) make a ton of sense. Cloud servers are overly expensive otherwise.
I have a prepared draft for a blog post exactly on the topic of cloud computing and deep learning. I did not finish it as I thought that there would not be much interest in the overall question since most people will just buy GTX cards. However, it seems that there is quite a confusion going on what makes sense and what does given certain circumstances. I think I will finish that blog post now and post it in the next days.
If you want me to discuss certain questions regarding deep learning hardware and cloud computing let me know here.
One problem with this argument is there isn't enough history. When aws added k80 the price of the old ones did not decrease much; they just increased the price of the new k80 higher than the k20. Theoretically what you said can happen, but Google still has to run the k80s and pay for them.
By the way, I appreciate the useful comments you've left in the past on your experience for gce.
Another option is to consider something that is even more abstracted from Google Cloud, AWS or Microsoft - such as, https://www.floydhub.com/ (Heroku for Deep learning). Ultimately, someone like them may be quicker to switch between different providers than individual companies.
There is an interesting offer by Hetzner that's available for some month now.
They provide a dedicated server with a GTX 1080 for ~99e/month (111$/month) with adequate CPU (i7-6700), 64G Memory, 500G disk space and 50TB Traffic - there are also on-demand offerings by GCP and AWS, but I do not think they can match the offer by Hetzner: https://www.hetzner.de/us/hosting/produkte_rootserver/ex51ss.... Keep in mind that I am talking about R&D, in particular training of networks - which has lower expectations on availability than e.g. later inference.
Disclosure: I am not affiliated with Hetzner and did not test it yet, but I have a ~40e dedicated machine there for occasional number crunching and everything worked so far (no availability or hardware issues).
Furthermore I am not sure about the exact specifications (Memory-Size of GPU) or if there are different types of 1080s that differ significantly in Deep Learning Performance (see also: https://github.com/jcjohnson/cnn-benchmarks).
I think signs are pointing to Vega being a HPC beast. But what they really need is the software ecosystem and support, and so far that hasn't been there. So while the new hardware looks cool, I'm really waiting for an announcement that OpenCL tooling got a lot better, or that CUDA is getting first-party support from AMD, anything to tempt those customers away from nvidia.
There's a real opportunity for AMD here if NVIDIA doesn't release a consumer variant of Volta because Titan X Pascal intentionally cripples FP16 performance to drive P100 adoption. It's the same sort of nonsense they pulled with crippling FP64 performance on GTX Titan (Maxwell) to drive K20/K40/K80 adoption, but it got old a long time ago.
What's more interesting is the disruptive change to the underlying programming model for Volta (thread-within-thread) that will break a lot of existing CUDA code without refactoring. So if there's no GeForce Volta option, I suspect a lot of that code won't get refactored. So Vega just needs to not suck and to deliver decent TensorFlow/Torch/Caffe performance to succeed as an alternative to NVIDIAopoly.
Not having fast FP64 is a design decision. Space isn't free, and FP64 takes up a lot of space that could be used on delivering higher FP32 perf, which is more important for video games.
Except that's not how it played out. The Tesla GPU all the way through Maxwell was just a different binning of the GeForce GPU, usually clocked lower for passive cooling and improved stability (sure, K80 is an exception, but K80 is a strange and tragic evolutionary dead-end IMO).
Tesla P100 was the first real HW-level divergence with its 2x FP16 support. But because we still can't have nice things, GTX 1080 was the first GPU with fast INT8/INT16 instructions, followed by the mostly identical except much more expensive Tesla P40. So we ended up with the marchitecture nonsense that P100 was for training as P40 is for inference despite being mostly identical except as noted above.
I'll assume Volta unifies INT8/INT16/FP16? And I think it's OK if the Tesla card has higher tensor core performance, but if the tensor core on GeForce is slower than its native FP16 support, I can only conclude NVIDIA now hates its own developers and has decided to sniff its own exhaust pipe. Isn't having to refactor all existing warp-level code for thread-within-thread enough complication for one GPU generation?
Also, if consumer Volta ends up with craptastic FP16 support (ala 1/64 perf in GP102 vs GP100, slower than emulating it with FP16 loads and FP32 math), NVIDIA will create a genuine opening for AMD to be the other GPU provider in deep learning.
CUDA is getting support from AMD in the form of HIP. In my opinion, the problem is different: even if AMD supported CUDA proper, that still won't lead them anywhere because the reason people use Nvidia is not so much CUDA itself (although it has good tools) but Nvidia's proprietary libraries: cuBLAS, cuDNN, cuFFT etc.
If AMD provided good implementations of similar libraries with OpenCL and shipped them with their drivers (similarily to Nvidia's CUDA toolkit) that would be much better than supporting CUDA, but leaving the ecosystem bare bones again...
There are even better independent open-source equivalents for some of those, but that is not the point. Good luck compiling some of AMD's clMath libraries without issues. Then, you're "just" left with packaging them properly. Performance is also not stellar compared to Nvidia. Meanwhile, when you install Nvidia's toolkit, you're set with everything.
The problem with OpenCL is the lack of well performing libraries, AMDs Core Math and Performance libraries are utter garbage still.
If you can't do what Blender did and write everything from scratch including your primatives you'll be much slower than CUDA.
But there is also a cost to it the Blender Cycles OpenCL code is nearly 5 times as big as their CUDA code and Cycles on OpenCL is still not at a feature parity with CUDA.
The change in branding would likely not yield much for it.
I haven't heard much about AMD's ACML and ArrayFire but I'm not surprised.
On the other hand, I think you're underestimating the fact that OpenCL is an open spec and therefore has support from the FOSS world. CUDA has always been criticized for being closed source.
Even though OpenCL doesn't get much praise, and actually get criticized a bit (I'm personally not a big fan because writing OpenCL code is like bending over backwards). It has a lot of potential with new libraries coming up[1] which can possibly make it atleast on par with CUDA. Once that happens, AMD's cost effective cards will put it in the race.
CUDA is tricky, it's not FOSS but it's also not completely "closed" source either it's just a restricted license.
Many of the core libraries are not exactly open but these are primitives.
If say cuDNN would become open source today there won't be any benefit from it, you won't be able to make it run faster than what NVIDIA has already achieved.
As for the vendor lock well this is tricky, AMD also tried to vendor lock their initial compute APIs they've fallen back on OpenCL because it wasn't working.
ROCm isn't exactly vendor neutral while it can run on nearly any OpenCL compatible hardware it's tailored and optimized for AMD GPUs which means it would run like utter garbage on anything else.
It also supports interoperability with CUDA via the HIP compiler.
And in all honest at least for scientific computing OpenACC (https://www.openacc.org/) might make this argument irrelevant at least as far as general use code protability goes.
[1] is actually AMD's old libraries. Judging by dev activity, it seems to be abandonware in favor of https://github.com/RadeonOpenCompute which is itself not ready for prime time.
ROCm is an amalgamation of a lot of things, some new some (very) old.
It still relies on many pretty old libraries with questionable performance at best.
The newer stuff is good but it's tailored to AMD GPUs, don't expect interoperability when it comes to any reasonable performance if you want to run ROCm OpenCL on NVIDIA or Intel hardware.
I am working on [dcompute](https://github.com/libmir/dcompute) which I hope will bring an equivalent experience when running on OpenCL and CUDA, and being written in D will provide all the advantages it does to writing kernels as it does with writing host code (with of course the ability to share compile time information across host and device). I believe that this levelling of the playing field will let the best hardware win.
The question is not AMD's processing power, the question is the tools available for AMD cards, which are scant to say the best.
While AMD doesn't create something like cuDNN to go along with their cards, no real work will start being done in porting most important DL libraries to AMD cards. And even in that case, it will be a lost generation for AMD, only in the 2nd generation where AMD actually offers a real alternative in DL to NVIDIA, you will start to see some real progress being done with it.
They stated at the analyst day that they will support TensorFlow, Theano, Caffee etc. And will release something called MiOpen.
They also stated this last year:
> On top of ROCm, deep-learning developers will soon have the opportunity to use a new open-source library of deep learning functions called MIOpen that AMD intends to release in the first quarter of next year. This library offers a range of functions pre-optimized for execution on Radeon Instinct cards, like convolution, pooling, activation, normalization, and tensor operations
That would be nice, more competition is better for the consumer. Still, it will affect purchasing decision only when it happens, and it hasn't happened yet.
They don't have an implementation of in-place convolutions AFAIK. The im2col trick may be too slow in practice (read x2.5-10 slower) to make any difference in terms of adoption. We already see this with Caffe and cl-Torch.
AMDs benchmarks are highly doubtful.
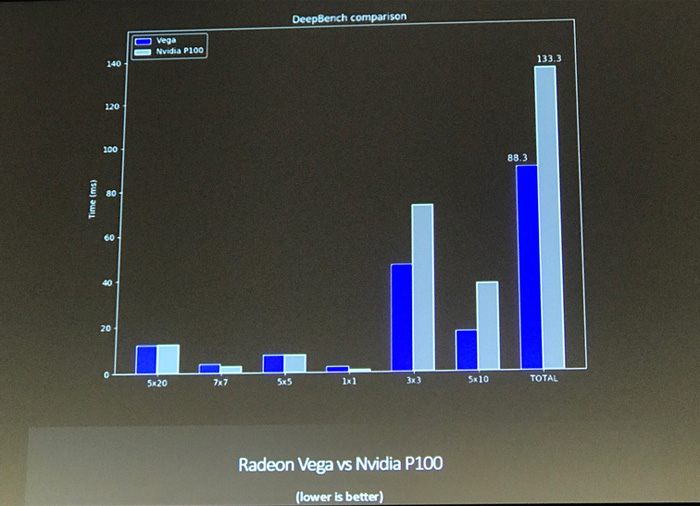
DeepBench isn't a benchmark it's a benchmarking tool they haven't released what dataset nor what code were they running.
Their SpecPerf View benchmarks were a total FUD they compared NVIDIAs consumer (GeForce) drivers against Radeon Pro drivers.
The SPV benchmarks look impressive until you realize they are lower than a Quadro M5000 which is based on the same Maxwell chip that drives the 980ti.
NVIDIA's consumer drivers (and the non Pro AMD ones) are simply horrible for CAD and other professional workloads.
AMD has been touting better performance than NVIDIA GPUs in compute since Fiji and they do not deliver.
It's also important to note that VEGA will have FP64 performance at 1/32 while the P100 is at 1/2.
I'm sure you can find an OpenCL workload that NVIDIA would be utterly trash in because the code is not optimized heck working with 256 batches as recommended for AMD rather than 1024 as recommended for NVIDIA would achive that alone.
If anyone here doesn't want to spend money on $500+ GPU (or the $1k+ ones!), then I'd suggest getting the lowest tier Nvidia GPU for $100~[1]
If that GPU is a real bottleneck for you, then you're much better off spending money on GCP/AWS's GPU offerings. That's because consumer GPUs get superseeded every year and online offering's price will only go down.
So you can spend 10% of $1k every year and keep getting better return on compute / dollar every year.
>If that GPU is a real bottleneck for you, then you're much better off spending money on GCP/AWS's GPU offerings. That's because consumer GPUs get superseeded every year and online offering's price will only go down.
GCP and AWS have old GPUs and they are really really expensive. If you expect to run workloads for a long time, it would be more cost efficient to buy your own hardware.
They are very, very few cases where getting an expensive GPU - anything more than a Nvidia 1060 would make financial sense.
The 1050 is a beginner card is it is perfectly fine to learn and run small nets. More importantly, you can decide if machine learning is for you. Then, comes to second investment, which is actually running real-world models.
Although the online GPU offering is expensive (you can also look around for cloud GPUs with lower SLA requirements for a lot cheaper) you'd be using them for a lot lesser time.
Even if you go with the big three, you can get good pricing if you look around. AWS has a single GPU with 1,536 CUDA cores and 4GB RAM. Looking at the Spot Pricing[1] which is $0.25 an hour, you can get 3000 hours of compute for $750, which is the price of 1080Ti (which is the most cost effective card on the market today).
Now, I would say, 3000 hours is more than enough time one needs to run whatever they want to. You can get a lot more if you go with some other service other than the big three.
If your usage exceeds that, then you are probably using it for commercial purposes, in which case you need to account for a lot more variables (downtime, maintenance, etc). Then you should also consider the deprecating perf/$ your GPU gives you every year over the new ones in the market - especially since the perf jump is a lot more than what we're seeing with CPUs.
If you are doing it for learning, I'd say you're doing something wrong, because you shouldn't need that much power. Also, consider the electricity costs and possible over usage of your computer.
* Setting up machine on AWS is more complicated than locally, and requires some admin skills.
* If you use spot instances, you need to handle checkpointing, which requires persistent storage, and all of this stuff requires even more admin skills
The goal of a person who starts working with deep learning is to learn deep learning, not how to setup machines, manage them, work with checkpoints, etc.
Also, don't forget that there's a large market for used GPUs and you can get real bargains.
>Setting up machine on AWS is more complicated than locally, and requires some admin skills.
There are tons of guides online where you can learn how to do so in <5 mins. Setting up the computer by yourself is more complicated I would say, and would take a first timer days rather than hours.
>If you use spot instances, you need to handle checkpointing
Again, not a big deal to learn.
>The goal of a person who starts working with deep learning is to learn deep learning, not how to setup machines, manage them, work with checkpoints, etc.
I mean, if you're buying a GPU and setting it up, you're more than likely assembling the computer by yourself. You'll also have to maintain it properly. Then you'll have to look for correct drivers and other software which can get frustrating (it did for me).
On the other hand, I just could use a step by step process for the AWS instances since they had a few specific types of GPUs and I didn't have to even think, just copy/paste the commands from the webpage to the terminal. There are even AMIs which setup everything for you, which would require even less effort, but I don't trust them so I go with a clean disk.
Moreover, learning how to use AWS is a much more valuable skill than putting together computers so time well invested I would say.
There is no reason, not to get a Pascal GPU at this point, the performance is simply superior. For a lot of models, we are talking about days of training time, so 20%-30% time saving is significant, and we are not even touching the part that large VRAM enables bigger batch size which you won't get in middle/low end GPUs.
You can get an 8GB GTX 1080 for 2/3rds the price and it offers 80% of the performance. If you don't need the 11GB of memory, it's a steal. If you're building a rig with multiple cards, 1080 might be an economical way to get great performance. If you're looking for maximal compute density, 1080 Ti is the way to go.
The power consumption of a 1080 is actually lower than a 780 or 980, plus a 1080 Ti uses about 50W more power when pinned, so I'm not sure where you're coming from here.
GTX drivers become crippled when the card detects the presence of a virtual environment. This means you can't run GTX in the cloud, otherwise, cloud GPU prices would be much lower. Without the availability of GTX, we've been trying just about everything at Paperspace to bring prices down and make the cloud a viable option for GPU compute. The argument being, there are real benefits to running in the cloud like on-demand scalability, lack of upkeep, minimal upfront costs, and of course, running a production application :) There are other indirect cost saving eg power consumption which can be quite significant when training models for long periods of time. Would love to see a total cost of ownership figure added to this post.
Unless you have an unlimited supply of free electricity and don't care about the increased hardware management overhead, it's a waste of money to buy Pascal GPUs for large-scale deep learning.
The following cards have much more optimized deep learning silicon and are publicly available /right now/:
- Nvidia Tesla V100 (Tensor cores only: 120 TFLOPS FP16)
- Google TPU2 (180 TFLOPS FP16)
Additionally, Intel Xeon chips with the Nervana deep learning accelerator built-in will probably be available early next year.
If you must control the physical hardware yourself and can't use cloud services, go buy Tesla V100s or wait for the Nervana Xeons.
That makes no sense as the TPU2 is not really out yet for actual consumers. AFAIK it's only in closed alpha right now, so if you're actually doing stuff right now it's not a real option. There's also no pricing so the "cost effective" remark can't really be seen.
AFAIK AMD has not announced any Tensor Processing Unit or specific tensor acceleration capability. nVidia Volta [0] does have a Tensor Processing core optimization.
'Tensor processing' isn't some special kind of compute. The TPUs (which were badly named by google) are just specifically designed ASICs with lower precision which have much lower power consumption than GPUs, therefore cost effective for inference, which google does more than anyone on earth.
'Tensor Processing Unit' has become some what a phrase used to confuse (trick?) people into thinking it's some new type of processing, but its not. If the GPU says it has a Tensor Processing Unit, it just means it operates with a lower precision, but you have to remember that the overall power consumption of the GPU doesn't really change at full use compared to using higher precision chips. So you're actually missing out on the cost effectiveness of using lower precision.
If anything the 'Tensor Processing Units' just take up unnecessary die space when included high higher precision units because they're bad for training compared to higher precision compute units.
That's not true. Previous gpus, like Pascal, have lower precision instructions for fp16 and int8. The tpu allows a 4x4 matrix multiply and accumulated in one clock cycle through special cores. They're physically different parts of the die.
But they're not a new paradigm as they are often stated in 'marketing talk'. Also, what are you referring to by 'tpu'? Google's TPU or nVidia's Tensor processing core? Because AFAIK, there aren't any details about TPU's processing pipeline other than that one paper about data center use.
I realize they are physical parts of the die, which is why I said in my last sentence about how they take up unnecessary die space. Why? Because that die space will be better used for higher precision FP units which will be useful in training, which is more important than inference for most of the people in this thread.
Tpu is what Nvidia and Google both call their low precision matrix multiply hardware. Your assessment of how the hardware can better be used is just your assessment. The reason they did this is because they realized that a large share of their professional users want this, and they're willing to pay. They'll likely have other versions of the card where the tpus aren't there, so you'll have that option as well. It's not a new paradigm, but it's absolutely new to have this type of computation in a single cycle at these clock rates.
Question: if I'm learning about neural networks and want to e.g. train a network to recognize MNIST digits, do I need a discrete graphics card (probably attached to a VPS that I would rent)? Or can I use the i5 Kaby Lake (which has an integrated GPU) in my laptop to train my network?
To train an NN to recognize MNIST digits you need any cpu made in the last 5 years. Last 10-20 years if you want to wait a little longer. MNIST recognition was first done by convolutional neural network in the late 90s.
As other people have said, for MNIST, CPU is fine. One core. You can get over 90% accuracy with a network with just 1 hidden layer with only a few seconds of training. Or something like that. If you've never played with MNIST before, it's kind of amazing how easy it is. For instance, the following idea "works", in that you get results that are pretty bad, but much better than chance. (Even more than 50% right, I think.) Suppose you have 10 arrays:
zeros: each element of this array is a picture of a "0"
ones: each element is a picture of a "1"
...
nines: each element is a "9"
Compute the average of each array: the "average" 0, the average 1, and so on. Then classify new digits based on which average element they are closest to, using Euclidean distance. This sounds way too dumb to do any good, but the MNIST digits are normalized so well that this actually does something.
Even better: you can have a neural "network" that has zero hidden layers. This actually achieves almost respectable performance, believe it or not.
Yes, it is just logistic regression. I just dug up my old code from a few weeks (months?) ago, and it seems that somewhere around 90% is not too hard. 60% is way too low, unless I'm measuring wrong somehow.
MNIST is a toy problem. It shouldn't take you more than a few days or even hours to completely understand it. Do yourself a favor and get a GPU because soon you will want to try bigger networks on real world images.
1060, 1070, or 1080Ti are all good choices, depending on your budget and ambitions.
You actually don't even need the iGPU for simple MNIST training. The CPU is enough. Check out the sample MNIST training example with Tensorflow.
If you are asking about using the iGPU for a bit more power, most frameworks don't support them. The only frameworks with which you can use with iGPUs are which have OpenCL support, like caffe[1] (even for those you need to have a recent enough CPU)
Tensorflow either uses CPU or CUDA (Not even AMD, but the support is coming for openCL)
On average it takes a SWE or DL engineer a few days to set up a unit from scratch. Your company probably burns over $2,000/day so every day your DL engineer or SWE isn't up and running costs you money.
For a hobbyist, it probably makes sense to just use some GPU instances on AWS. But it doesn't really take that long for it to become cost-effective to buy a GPU. It only takes a couple of months of full-time use before it becomes cost-effective to purchase the GPU. Even if you're building the entire machine from scratch it takes under a year. (At least, that was my estimate when I was building a rig earlier this year.) If you're doing any serious deep learning projects it's pretty easy to have a model training nearly 100% of the time.
It is not that bad. Either you've your training data local (unlikely) or it is already available in the "cloud" (i.e. a public-facing service). Let's say a typical training set (raw data) is 100G.
Assuming 2.5MB/s Upload capacity with local data, you've uploaded it to your deep learning machine in half a day (100000 / 2.5 / 3600 ~ 11 hours) - which is not that much, as most of your time will be used for development and fine-tuning of your deep learning tool chain anyway. In most cases the data is accessible via a public-facing service, and assuming 1GBit/s bandwidth you've downloaded 100G in 13 minutes (100000 / 125 / 60 ~ 13 minutes).
I know egress is one of the more expensive cloud services (e.g. compared to compute and storgage) at AWS, GCP, etc., but if I upload data to my learning system that's ingress AFAIK which is mostly free or less expensive. Btw. current Egress is like 0.1$/GB, so 100G ~ 10$.
Don't get me wrong, I am not saying you should always train in the cloud, but I do not think slower Upload or Ingress are the limiting factor.
extremely frustrating. Internet service is getting worse this in country, not better, sadly. The only lucky ones are those who live in competitive markets (lol) and those who had google fiber break some ground.
The anti-competitiveness is getting worse too. Charter just took over TWC in my area.
If you're doing a lot of experimentation, it can make more sense to train your models locally (so you're not paying server / data transfer costs every time you test).
1. Can laptops with, say NVidia 1070 or 1080 GPUs keep them cool at their stock frequencies for a few hours? My work laptop with non-U i7 (Thinkpad T440p) starts thermal throttling in just a few minutes when I compile something large.
2. Wouldn't two NVidia 1060 or 1070 outperform a single 1080 for training, assuming batch size is kept low enough so that each batch fits in a single card's memory?
1. Depends on the laptop really. Some have better cooling than others. I'm training models for a few hours every day with an asus rog that has a 1060, and I'm not experiencing any throttling.
Two 1080TIs are way better than one Titan Xp and cost about the same (2x$700 vs $1200). Each TI has 11GB of RAM vs the TitanX's 12GB, and each TI is nearly as fast.
At the NVIDIA conference all the second tier hosting companies were promoting the P100 (at NVIDIAs insistence) but when pressured admitted that their big customers now deploy 1080TIs. Paying for P100s is sort of a clown move even if you're spending someone else's money. The P100 starts at like 10x the price of the 1080TI and isn't much faster and again has just 12GB of RAM (16GB if you pay $4000 more, ludicrous)
Usually, but the caveat is they are only better for workloads that are easily paralizable (like hyperparameter search). Multi-gpu models are still very complicated in my experience. And the Xp is a bit faster and has 1gb more memory, which is useful in some edge cases (like large or 3D covnets)
Also if there do build with multiple gpus, watch out that you can give both cards a full 16 pci lanes, not a given in a lot of motherboards.
Details https://arstechnica.com/gadgets/2017/04/nvidia-titan-xp-gp-1... If your machine learning problem is sized to fit 12GB better than 11GB, it could save a lot of time. But unless you're really in a hurry, it's still probably not worth the huge price bump.
I recently bought an Alienware 13 R3 for deep learning (okay, and gaming...) and I'm quite satisfied so far. In addition to the built-in Titan 1060 with 6 GB of DDR5 it's possible to get an external graphics accelerator for additional performance as well (I haven't tried this yet though).
K80s and K40s have a K. That's two generations old. We are currently on P and about to be V. If you think K80s are good, you are far far behind the times in machine learning. A single 1080Ti even in a 4U server outperforms 2 K80s.
Dell R720 / R730s, dual GPU (typically with K40m or K80) in there with 1100W dual redundant PSUs and the GPU enablement kit.
We also set our fans to constant 70% min, to keep the airflow good.
They actually work 15% faster on average compared to the Tesla K series (Remember it's a 5 year old card), but they just stop working after a few months, or return inconsistent results for some operations.
Now, we're not doing graphics with them. We have a GPU database called SQream DB - and we depend on the results to be correct. In the end, they didn't make a lot of sense for us to deploy in a production environment, so back to the Tesla series we went.
In a tensorflow job I find it hard to imagine that a memory error would make a jot of difference... wouldn't the error simply be removed by the network training? If the error was in the execution then I imagine that the epoch would fail and it would then just be a matter of restarting.
{kind=link}
I saw a lot of "should we use Cloud, no its crazy a GPU only costs $X". The key is that if you believe GPUs are going to get updated every year, and/or the best thing for ML may change (see TPU and plenty of startups with custom hardware) then suddenly buying hardware for 24? 36? months isn't as obvious.
We (and AWS and Microsoft) have K80s because Maxwell wasn't a sufficiently friendly all around part. We're all going to offer Pascal P100s and in the future V100s. The challenge for buying your own is that P100s are available now-ish and V100s may be available in less than 12 months.
Buying a P100 or similar part today doesn't mean it won't still be working in a year, but it will suddenly mean you've bought a part that now has much worse !/$ in just N months. If you have an accounting team that is spreading your $Xk over those 36 months, the reality is that you have two options: tell everyone they have to make use the old parts ("we're not buying new GPUs until it's been 36 months!") or realize you're going to get a lot less use out of them.
To be clear, the progress in this space is really impressive. And the same problem above applies to us (the cloud providers). Despite my obvious bias, if I were fired today, I'd be renting to do deep learning just based on the roadmap alone (not to mention the ability to suddenly spin up and down).
Again, Disclosure: I work on Google Cloud and want to sell you things that train ML models :).