You have a faster CPU. "SSE sdot" and "SSE+tiling" are both faster on your machine. However, "Eigen" is slower. This suggests gpderetta might be right – MSVC is not as good as gcc to optimize Eigen, or conversely, Eigen has not been optimized for MSVC. Nonetheless, MSVC did fully vectorize the inner loop of non-SSE sdot, better than both gcc and clang (EDIT: of the versions I was using; it would be good to try the latest gcc/clang). It seems that explicit SSE vectorization is the most stable. Other implementations of "sdot" depend too much on the behavior of compilers.
Anyway, thanks a lot for this experiment. I rarely use MSVC these days. It is good to know where it stands.
Both CPUs are same microarch, Haswell. Xeon has much more cache. The i5 has higher base frequency (3.2 vs 2.6) the Xeon however has higher turbo frequency (3.6 vs 3.4).
OK, I’ve installed Cygwin and GCC, compiled and benchmarked the original code. I made the following changes in the makefile: (1) Replaced -O2 with -O3 (2) added -msse -msse2 -msse3 -mssse3 -msse4 -msse4.1 to the option, both C and C++.
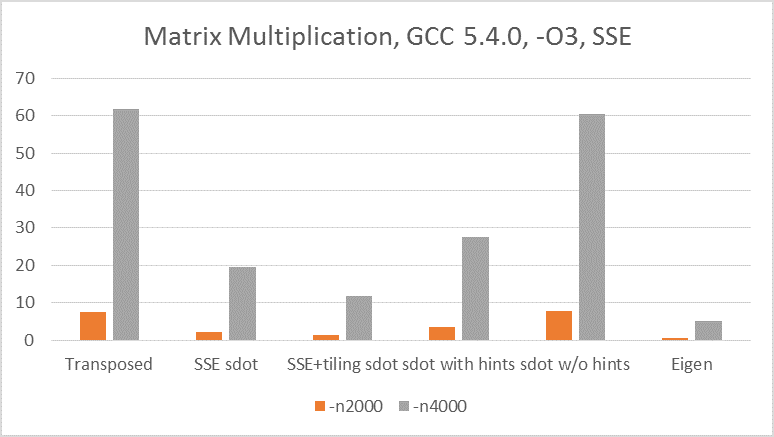
The results on GCC/i5/Windows 10 are very consistent with the OPs result on GCC/Xeon/Linux.
> Apparently, the main reason for your results — GCC optimizer ain’t good.
while that could be the case, it does not follow from your results; you need to compare GCC and MSVC directly. It might rather be that MSVC is not capable to optimize Eigen enough to give it a larger advantage over SSE+tiling.
From experience MSVC is less capable of aggressive abstraction elimination (the bread and butter of Eigen) than GCC.
OK, did that. Results for GCC are very close to the OP’s results for Xeon.
GCC indeed did better optimization of Eigen than MSVC. Specifically, about 25% better. I think that might be because authors of Eigen have very intimate knowledge on GCC’s optimizer, and somehow specifically optimized their code for GCC compiler.
However, for the rest of the test cases, MSVC performed much better. For example, for Transposed algorithm, MSVC result is 3.5 times faster - huge difference.
{kind=link}
Here’s Visual C++ port: https://github.com/Const-me/matmul/
Eugen is still faster than naïve implementations, but not that faster, just 30-40% compared to SSE+tiling sdot.