I'm pretty skeptical of using bzip2 as the entropy coder compared to DEFLATE as used in PNG. bzip2 is really slow. Also I would hope that an image format designed in 2016 would admit some degree of parallel decoding, but by leaning so heavily on a slow entropy coder they also killed all parallelism opportunities.
Browsers routinely spend as much time in image decoding as they do in layout, so this matters.
If you want a purely entropy coded format with a trivial, easily memorizable file format, just use PNG with all scanlines set to the None filter, one IDAT chunk, and one IEND chunk. Totally trivial, and probably simpler because DEFLATE is a relatively simple format.
> I'm pretty skeptical of using bzip2 as the entropy coder compared to DEFLATE as used in PNG.
Or compared to xz. bzip2 seems completely obsolete: gzip provides much faster compression and decompression, and xz provides better compression ratios with faster decompression. Not to mention new algorithms like brotli.
Even though it's optimized for text, doesn't mean it's not also better for binary. For instance it's also used for binary font files in WOFF2 and seems to perform very well.
The simplicity of the approach means that, given that the compressor is not baked into the format, it is readily exchangeable without having to change Farbfeld. In addition, nothing stops someone from creating an optimized compression format and bring it in with the same ease.
Why not just have that compression format be PNG filtering + DEFLATE? PNG filtering is extremely simple and is probably implementable in two dozen lines of code. It's nothing compared to the complexity of the entropy coder.
At that point you might as well just be a subset of PNG, which is nice for interoperability anyway.
I'm not really an expert on the matter, but couldn't PNG filtering be implemented in the same way, i.e. as a filter just like Farbfeld? This way it would keep the same composability, and be used with other formats too.
Considering there are no stand-alone implementation of these, I guess the author simply went with what achieved the highest compression ratio, regardless of speed.
But it would be interesting to see if a complete ecosystem can pop up around it sooner or later, especially given the renewed interest in arguments between "the unix way" and other philosophies.
You could use PNG filtering in other formats, sure. I don't know why you wouldn't just use PNG at that point, though. The only difference between this and PNG is the chunk format to encode IHDR, IDAT, and IEND (which is really easy) and a handful of extra bytes in the IHDR chunk to specify truecolor mode and so forth.
The truecolor-with-no-extra-chunks subset of PNG is incredibly simple.
>The author has yet to see an example of an image which looked any different in the print depending on if it had been processed in a sRGB or Adobe RGB pipeline.
The author clearly has very limited experience of professional printing.
Images aren't just used by photographers. They're used by graphic designers, digital artists, and other people who need a consistent wide-gamut colour space.
sRGB is not that colour space.
Referring to a couple of ancient Ken Rockwell blog pages as "proof" is simply uninformed and amateurish.
You can also use AdobeRGB with Farbfeld, but from my experience, those photographers shooting and printing in AdobeRGB with late CMYK export have Photoshop/PhotoRAW as their pipeline.
If you fuck one thing up trying to handle AdobeRGB in farbfeld, everything is fucked up, but that happens anywhere.
On the other hand, most photographers shoot their stuff in sRGB (for a fact, because sRGB is by far the most widespread).
I don't want to insult the professionals or something, I'm just acknowledging the fact that for the 1% using AdobeRGB there's no reason to complicate the format.
The fact that this file format doesn't enclose the AdobeRGB vs sRGB information is a deal breaker.
A lot of computer vision research datasets uses a similar file format - so I can see its use there. But things like movie creation, publishing, etc will probably never adopt this.
Indeed. I'll reiterate - it's vital that images have a known color space. Even if OP just states that farbfield is sRGB, it'll help. Otherwise, you've only got a 3D matrix, rather than an image.
You can assume that most people are using sRGB colourspace for now, but it may not be true in the coming years, especially with UHD TV being officially specified and adopting Rec. 2020 colourspace: http://www.businesswire.com/news/home/20160104006605/en/UHD-...
I think it's nice to have a simple format for storing images for the sake of being able to build a pipeline of filters that are very lightweight and simple to implement.
But I was really distracted by how the author kept going on borderline nonsensical tangents about compression. There's a reason we usually build compression into the file format, instead of just zipping a lossless bitmap. It turns out that there's a ton of stuff you can do to exploit redundancy in two dimensions - if you can apply a transformation before the compression stage.
And yeah, you can make up some of your losses by using bzip2. But again, there's a reason formats like PNG don't do that: it's slow.
The bzip2 choice is not set in stone. The reason why PNG is built on top of deflate is because back then there was nothing better around for the computing power available.
If you talk about speeds, the more or less only revelant measure is _decompression_ speed, and bzip2 is just fine for that. How long it takes to compress an image is relevant only once. Decompression is another story.
Additionally, in pipelines, you would only decompress your image once and compress it once. Usually, when people build pipelines based on individual tools passing png's to each other, these steps are repeated n times for n elements of the pipeline.
Well, you can compare it to compressed RAW files, which are probably the closest we've come in terms of lossless compression. Then again, from a photography point of view, I do really like metadata, and I see no reason to omit them.
If I understand correctly farbenfeld is designed for processing images, not storing them. And if you bzip a farbenfeld image you might as well do it with a separate json file for metadata.
No and no.
If you discard metadata (e.g. EXIF from a camera) upon conversion, they don't come back after "processing". And bzip compresses a single file, not two; it is commonly used along with tar to make compressed multi-file archives.
Why would you discard metadata? What I'm saying is you should be able to extract it to a separate file when converting to ff. You're right about bzip and tar, but that just adds one extra step.
Won't be using this suckless format. Pretty useless. The real image formats took effort and are mature. This is just a more compact, less useful hacked out version of netpbm etc. Being easy to parse is no particular virtue. Use libraries with good APIs.
I've always thought of suckless.org tools as more of an educational tool than anything. Certainly some people use them in their day to day lives but for me it's always been like "What's the simplest way to do X?" It gets you thinking about the complexity of modern software and hopefully makes you question your assumptions. But yeah, pretty useless.
"The real image formats took effort and are mature. This is just a more compact, less useful hacked out version of netpbm etc."
That seems less like "criticism" and more like "a summary of the blog post". (Sorry, I have to admit I'm developing a pet peeve around people echoing back things the original author already said but acting like it's a new criticism.)
This seems likely to be unsuitable for large files (e.g. 50000x50000 pixels) because the external compression is going to make random access difficult. So extracting or displaying a small part of the image means you have to read from the beginning.
You need to use a compression format that has sync points. For example, if you need to seek to 1GB in the uncompressed file, the compression itself needs to have recorded where that corresponds to in the compressed file.
zlib apparently supports the `Z_FULL_FLUSH` sync option which you can use at compression time to provide sync points. (I haven't used it, and it doesn't seem to be exposed by GNU gzip.) Other compression formats might have something similar.
Most people in the comments clearly do not understand the words "easy" and "straightforward". I can only recommend them to go to the nearest dictionary and look at those words carefully.
Personally, a tool like this is what I always wanted to have during my Engineering Master and Machine Learning PhD. A clear, simple, straightforward & easy format so that I could process my images easily, simply, clearly and straightforwardly.
The only small complaint I can make is the use of BE that requires a manual transform to an "actual" integer.
I was skeptical about the claims of competitive compression, but in a handful of experiments it looks like farbfeld+bzip2 got slightly better compression than png (after running through pngcrush). Decoding took an unfortunate number of milliseconds, though.
(Give it a try! The tools are right there in the git repo, and quite easy to use.)
I'm sure the designers of PNG were aware that slower entropy coders that gave better compression ratios existed. But there's a reason they didn't choose them: bzip2 is 5x slower than DEFLATE even on the lowest setting. Scanline filtering, on the other hand, is fast, amenable to SIMD, and even parallelizable if the image is properly encoded. It's also easy: the only thing I don't remember off the top of my head is the order ties are broken in the Paeth filter.
bzip2 is an especially poor choice in 2016 given that it's inferior to LZMA in both speed and quality.
thing is, bzip2 is widespread, unlike lzma not everybody has.
on a technical side, lzma is a better choice. I might add a lzma recommendation, however, in soma cases lzma performs worse than bzip2.
also, decompression speeds matter, not compression speeds.
in the end, use what you prefer. the compression is not mandated by the spec.
the main use for farbfeld is also rather thought to be as a piping format. it could also be used for storage, but that's not the main point.
I will try this format next time I write a simple image processing program. Piping with the converters is way nicer than linking against libpng. PPM is OK but this format is so dead simple I can commit it to memory. Big endian seems anachronistic though, why?
Nowadays, most computers use Little Endian, however, that might change in the future.
Also, there's no justification to write software only for one endianness due to speed(tm) or something. Learn to use the interfaces provided by the system (htons(),htonl(),ntohs(),ntohl(),...)
and when you specify interchange formats, specify an endianness.
Which one it actually is doesn't matter, there's not too much magic happening in the background anyway. Those people claiming "Little Endian Master Race" might probably jump on the Big Endian bandwaggon as soon as it became the majority for some reason.
In fact though, writing endian independent code is the way to go.
Of course, but right now almost every machine uses x86 or ARM and I want to write a throwaway image processing program. It just seems like a weird choice because the format is almost effortless to use otherwise. You gotta pick one endianness, why not pick the one that's on every machine right now?
If you're going to go with 16 bits per component, please at least increase the color gamut. sRGB is fine if you can only dedicate 8 bits per component, but with 16 bits per component the extra depth is more useful as an increase in the color space rather than only greater precision.
I've investigated this topic for a while. I've been thinking about adding a mandated wide gamut color space.
Even though the wide color spaces "destroy" accuracy in small gradients, it doesn't matter when using 16-Bit. And because farbfeld is 16 Bits, it would definitely be an option.
Care to hit me with a mail (you can find it at the bottom of the page) so I can write you in a more sensible way what I've been thinking. Maybe you can help me decide on which color space to use (Adobe RGB, ProPhoto RGB, ...).
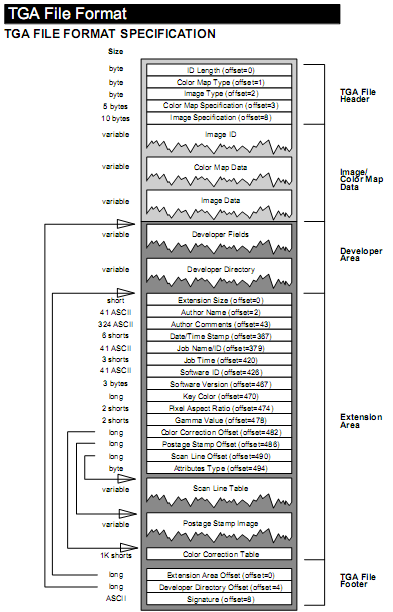
The idea is very sensible. Using an image format that's trivial (and fast) to read and write makes it easy to build custom image-processing pipelines. The video game industry used to (and maybe still does) use Truevision TGA format, in uncompressed true-color mode, to meet this use case. https://en.wikipedia.org/wiki/Truevision_TGA
TGA currently has the advantage over Farbfeld that many image editors and viewers can already read it, which means you can look at the intermediate results in your pipeline without having to convert them to PNG or whatever first. But Farbfeld has the advantage of utter simplicity.
If you're using Farbfeld as an internal format for your custom image processing pipeline, which is the use case I was describing, then constant explanation isn't a problem.
Not every image format needs to be suitable for use as general-purpose distribution format.
I've got a soft spot for simple, sane formats like this. One obvious but still simple generalization would be to allow n-dimensional image data by encoding the number of dimensions first, then the size of each dimension, then the data. That would allow representing video (very inefficiently), 3D static images (e.g. from MRI scans), and even 3D video (which is 4D).
Current image formats have integrated compression, making it complicated to read the image data. One is forced to use complex libraries like libpng, libjpeg, libjpeg-turbo, giflib and others
...
Dependencies
libpng
libjpeg-turbo
That's a bit of a non sequitur.
Aside from that, the arguments put forth aren't very convincing; the "integrated compression" is what makes compressed formats more efficient, since these are specialised compression algorithms adapted for image data. PNG, for example, uses a differencing filter. I think me and many others have tried ZIP'ing or RAR'ing uncompressed BMPs before, and found the compression is not as good as PNG. This is not even mentioning the possibility of lossy compression.
So it's a 16 bit RGBA bitmap with no support for custom headers, internal tiling, custom bands, band interleaving, or overviews. or compression. Simplicity is great and all, but all those features are actually really useful things to have...
What do you need custom headers for? I think this problem is better solved with tagging file systems.
BIP/BSQ Image Encoding can be done just well (you have (2^16)^3 colors), but you need to leave the interpretation to the outside. It is definitely not in scope of this format to handle that internally.
Compression is external, so yeah, it definitely can be used.
All the things you presented are useful to have, but the question is: For which percentage of people is it useful to have? Is it solved by something else in a better way?
You can never please the 1% without making everything harder for the 99%.
I'm probably in that 1% you mentioned. I work with large aerial photos (usually >10000x10000) with varying numbers of bands. Headers are excellent for georeferencing, storing band information, attribution etc.
> tagging file systems
Like HFS+? I'm somewhat ignorant, not sure what other filesystems support this. What tools do? I have no idea if I rsync a file from my mac to a server, and back to a Windows box, if you'll still be able to see the metadata. This strikes me as a huge weakness compared to just supporting internal headers like every other image format.
As others in this thread have said, it's a format for image filtering, not storage. Headers and compression get in the way when all you really need is a matrix of pixels.
I'm a bit flummuxed. Two things stick out. Firstly, PPM is widely used in these contexts. Its just not shouted about. Second, when PPM isn't used, its because its neither YCbCr nor YUV; I've found y2m an easy format. However, its not atypical to just use eat jpeg directly.
its always mystified me why there are not more standardised, simple things. when i load an image i want width, height and rgba in a buffer. complicated extras shouldn't be necessary to load an image.
this is why i use stb_image.c - even though it doesn't cover everything - it has a sane interface instead of a nightmare like libpng or libjpeg.
most image formats and the 'standard' libraries for using them look like a great reason to never employ anyone who had anything to do with them. this one looks like an engineer, competent at the most basic levels, did the most obvious thing.
good work.
given that most modern app formats do compression anyway i'm not sure there is any need to care about that. pngs don't shrink much inside an ipa or apk but raw data shrinks to about the same size as png in my experience.
That's an 18 byte header and then a list of pixel values. Everything else is optional and for the price of those 18 bytes you get an image format that you won't have to convert every time you want to look at it.
I also noticed that in my tests, thus I stressed this point in the FAQ.
If you try LZMA, you'll see that it sometimes is actually worse than bzip2, even though the latter is regarded to be quite aged compared to the former.
Actually, you can have images with up to (2^32-1)(2^32-1) pixels.
Given each pixel stores 64 Bits of data, there are 2^64 combinations for each pixel, yielding in the total number of possible images as:
I meant 2R,2G,2B,2A images, i.e. 8 bit per pixel. That was my misreading - it is actually 2 bytes per channel, (I'm used to image color depths being quoted in bits.) I need to read more carefully, sorry.
would be nice to be able to verify the header before running it through decompression. i can easily get a hold of 150MP images and they can be a pain to hack on.
If you just want to read in the header data, it should be sufficient if you just piped the decompressed data to your "header-checker" like this
bzip2 < giantimage.ff.bz2 | header-checker
Inside the header checker, you just read in the first 16 Bytes ("farbfeld" + width + height), do whatever you like with the data and exit.
bzip2 would then receive an SIGPIPE. Up until this point, it would have probably filled the pipe buffer (~16K) with data and then blocked.
Receiving SIGPIPE, I'm certain bzip2(1) will cancel any further decompression attempts.
You see, you could even carry on with your image-processing in case you like the header data and want to proceed. The nice pipe-system already handles that for you. :)
I think what he's saying is that you must decompress the entire thing before you can look at those headers. If all you want is the width and height, you still might have to decompress a gigantic image, which is lots of wasted work and time.
yeah, that was a bit strange. By choosing Little Endian, the author would achieve the ability to mmap an uncompressed image file to memory and then use it directly like an array in all contemporary hardware architectures. Not that it's a big deal, but I fail to see why would anyone choose Big Endian in 2016.
how come people assume there are only Little Endian machines. This mmap-technique wouldn't work on Big Endian like this, this is inaccetable!
However, you can still mmap and properly call ntohs() on each color channel value (if you access it). These functions won't hurt performance too much anyway, if at all. If you show me a measurable difference between using LE and BE, I owe you a beer, okay? :)
People are making the (valid) assumption that LE is far more common than BE.
On x86 swapping endianness is one instruction (BSWAP), but AFAIK it can't be SIMD'd easily. Given that SIMD is one of the things that can greatly speed up image processing, I don't think it "won't hurt performance too much"...
(Just FYI, this only works with SSSE3+, which to be fair is essentially all x86 machines. It's also >1 cycle on mobile x86 chips, which is very frustrating.)
{kind=link}
Browsers routinely spend as much time in image decoding as they do in layout, so this matters.
If you want a purely entropy coded format with a trivial, easily memorizable file format, just use PNG with all scanlines set to the None filter, one IDAT chunk, and one IEND chunk. Totally trivial, and probably simpler because DEFLATE is a relatively simple format.