Translating a solution from one problem domain to another is called "transfer" in cognitive science. There's some theoretical and empirical work done on the topic of transfer (e.g. https://www.tandfonline.com/doi/full/10.1080/135467808024901...) but as far as I'm aware, there is not a mature "general theory of transfer" that can be computationally implemented. That's still in the fictional "Glass Bead Game" territory. However, you may want to take a look at that literature for broader picture theory on the issue. It's closely related to the fairly vast literature on insight problem solving, which you might be interested in.
The author builds up plots step by step, showing the changes to the plot along the way. It's really great at showing what each element contributes to the final plot.
Not to take away from some of these comments, but the article does not mention anything about casual observation of the eyes signalling mental health issues. The article is highlighting research on diagnosing disorders of the brain using ophthalmological methods (e.g. optical coherence tomography to measure retinal thickness, electroretinography to measure electrical signaling in rods and cones, and angiography to assess retinal vasculature). Apparently, these non-invasive methods may be used as an additional diagnostic tool in diagnosis of a variety of disorders, and may even be early indicators of brain disorders that have not yet manifested themselves in psychological disturbances.
>and may even be early indicators of brain disorders that have not yet manifested themselves in psychological disturbances
It's only a matter of time before someone as unscrupulous as ClearviewAI develops a phrenology tool for identifying psychological disturbances based on "crazy eyes", which will be used extensively by state security services to manufacture suspicion where none is warranted. False positives are a feature not a bug. See, e.g. drug sniffing dogs and [1].
This article will be cited in the marketing material. It will not matter one iota that the research does not actually support that kind of application.
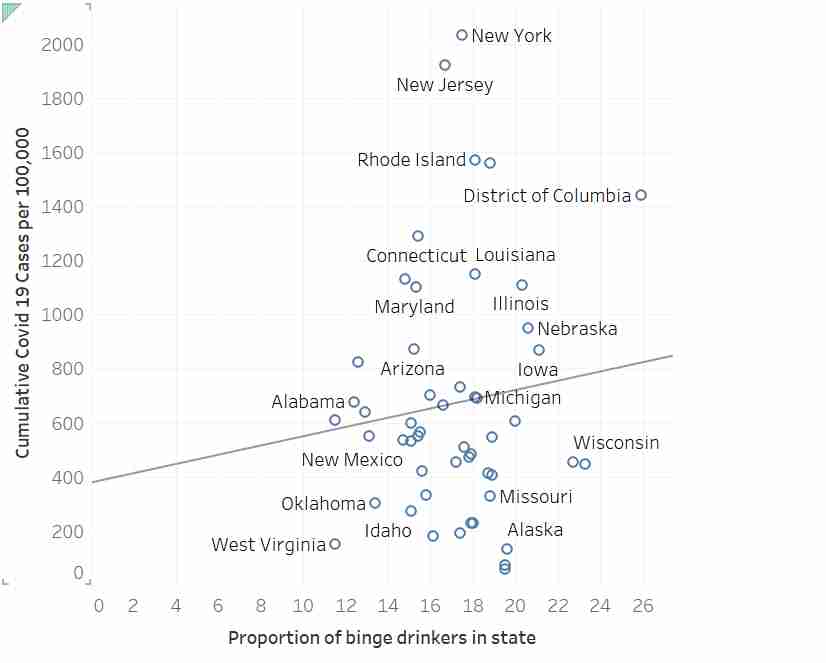
Agreed. I was curious enough to run the model myself so I used a tool to extract the data. The slope estimate (b=17.24) is not significantly different from zero, p=.437.
In case anyone is interested, below is R code to read these data and compute the regression. The summary() reveals the p value for the slope to be 0.437, and that for the intercept to be 0.32.
d <- read.table("https://pastebin.com/raw/HhWTKZRb", header=TRUE)
m <- lm(cumulative_covid19_per100000~proportion_binge_drinkers, data=d)
summary(m)
The problem is that the author is essentially claiming that running the regression for data not passing his eyeball test is, in itself, a misuse of regression...which is nonsense.
I'm not sure I understand your point. Did you actually look at the regression line through the data? It looks crazy off. I'm not a statistician but that line looks like it doesn't represent that data very well at all. People area also saying nuanced comments above but the underlying fact seems to be that this is not a good use of linear regression, and there is no strong correlation between the two axes.
Without access to the residuals, I'd still venture to guess that the assumptions of the regression are not severely violated in this data set.
When this regression is conducted, the null hypothesis is not rejected (regression slope not significantly different than zero). If someone is somehow arguing this regression rejects the null hypothesis, then they would be incorrect. But there is nothing wrong with using regression here. Its kind of the whole point. This is basic regression statistics 101.
Error bands on the regression slope would help people understand the uncertainty of the apparent slope.
Eyeball tests are often misleading, or fail to detect weak correlations (or deviations from model assumptions such as heteroskedasticity). That's why we check with more formal methods.
What are some examples of data sets with high(ish) r with high p (low confidence), and low p (high confidence) with low r?
I guess it would be a very tall, "sharp cornered" parallelogram of data points (clear slope at the average, but high error variation), vs a very short, wide rectangle?
I feel the same way. I think this explanation of the transition has been mentioned on HN before:
1) The Internet was created. Early adopters are generally optimistic about its potential to share knowledge and data, and form communities around mutual interests.
2) People begin to realize different ways to create money from this popular new technology, leading to very obvious attempts at creating revenue at some expense of users attention (e.g. advertising), followed by more hidden ways of revenue creation (e.g. selling data).
I also find it hard not to despair. There are still online communities that are still more motivated by communicating and sharing for their own sake (HN included), which I think should be the aspiration of online communities. Most people here have probably just settled into the online communities/blogs that serve these more optimistic goals. The unfortunate thing is that as soon as these communities become relatively popular in any way, other motives start to come to the fore to take advantage of that popularity. As those motives become clear, cynicism is inevitable. It seems to me that you might need something like benevolent community leaders that want to pour their own resources (time and/or money) into online communities without expecting anything in return.
I guess this comment didn't really offer ways to deal with cynicism regarding technology, if anything I justified the cynicism and suggested an option to create communities that would not breed cynicism.
My non-engineer guess is that a nylon brush would be shaved down pretty quickly by rail contact at typical train speeds, so that it would be ineffective at removing debris after a very short time.
Plus I imagine it'll apply nowhere near as much pressure on the track, so you'd end up needing a lot of brushes and then they'd all be wearing down quickly at 60mph or so.
The main results are an interaction between Time (pre/post) and Diary condition (3rd person/1st person), t = 2.65, p = .008. They followed this up with a contrast showing that the 3rd person diary condition resulted in more wise reasoning post-intervention (as compared to pre-intervention), B = 0.130, SE = 0.028, t = 4.61, p < 0.0001. And importantly, this same improvement was not seen in the 1st person diary control group: B = 0.022, SE = 0.030, t = 0.74, p = 0.458.
They didn't provide degrees of freedom for their t-tests, but given their sample size (N=298) they're essentially z-tests anyway.
Sure, there is subjectivity in the ways researchers operationalize the concepts that they study. That doesn't mean that their research is not "real science". If the study is of sound design and the result is replicable, it ought to be called science.
Regarding the self-measurements influencing the results: the wisdom in the participants' reasoning (the dependent variable in the focal study) was evaluated by two independent hypothesis-blind raters. This seems like a pretty solid evaluation of the participants which should be immune to anything but the manipulation the researchers employed (the diary conditions). I am not sure what self-measurement you are concerned about.
{kind=link}