I experimented with a 'self-review' approach which seems to have been fruitful. E.g.: I said Lelu from The Fifth Element has long hair. GPT 4o in chat mode agreed. The GPT 4o in self-review mode disagreed (reviewer was right). The reviewer basically looks over the convo and appends a note
I wrote this to argue that the GPT-5 rollout backlash wasn't just users hating change, but a rational response to a functional product downgrade.
My thesis is that "personality is utility." The collaborative "vibe" of 4o wasn't a bug; it was a feature that produced better results. OpenAI replaced a transparent creative partner with an opaque, cost-optimized answer engine and was surprised when users revolted.
I've tried to ground this by connecting the emotional Reddit posts to the concrete frustrations of experts who were all complaining about the same loss of agency and transparency, just in different terms. Curious to hear your thoughts.
Recently I started delegating small bug fixes and feature requests to a coding agent (Qoder) running locally on my repo. In my setup, it drafts specs collaboratively, edits files, runs unit tests, builds the project, and verifies results before I review diffs. In many cases, the first candidate passed all tests, which surprised me given my experience with AI coding tools so far.
- I start by pasting the user’s GitHub issue/feature request text verbatim into the chat.
- The agent extracts requirements and proposes a structured spec (inputs/outputs, edge cases, validation).
- I point out gaps or constraints (compatibility, performance, migration); the agent updates the spec.
- We iterate 1–3 rounds until the spec is tight. That spec becomes the single source of truth for the change.
After that, the agent processes the task:
1) Action flow: It plans To‑dos from the agreed spec, edits code across files, and shows a live diff view for each change.
2) Validation: It runs unit tests and a full compile/build, then iterates on failures until green.
3) Task report: I get a checklist of what changed, what tests ran, and why the solution converged.
Engineering details that made this work in a real codebase
- Codebase‑aware retrieval: Beyond plain embeddings, it combines server-side vector search with a local code graph (functions/classes/modules and their relationships). That surfaces call sites and definitions even when names/text don’t match directly.
- Repo Wiki: It pre-indexes architectural knowledge and design docs so queries like “where does X get validated?” don’t require expensive full-text scans every time.
- Real-time updates: Indexing and graph stay in sync with local edits and branch changes within seconds, so suggestions reflect the current workspace state.
- Autonomous validation: It tests and build steps run automatically, failures are fixed iteratively, and only then do I review diffs.
- Memory: It learns repo idioms and past errors so repeated categories of fixes converge faster.
What went well
- For several recent fixes, the first change set passed tests and compiled successfully.
- The agent often proposed adjacent edits (docs/tests/config) I might have postponed, reducing follow-up churn.
- Less context switching: The “spec → change → validate” loop happens in one place.
Where it needed human oversight
- Ambiguous specs. If acceptance criteria are fuzzy, the agent optimizes for the wrong target. Co-authoring the spec quickly fixes this.
- Flaky tests or environment-specific steps still need maintainer judgment.
- Non-functional constraints (performance, API stability, compatibility) must be stated explicitly.
I’m also interested in perspectives from OSS maintainers and others who have tried similar setups—what evidence would make AI‑assisted PRs acceptable, and where these approaches tend to break (for example monorepos, cross‑language boundaries, or test infrastructure).
A big problem with the chat apps (ChatGPT; Claude.ai) is the weird context window hijinks. Especially ChatGPT does wild stuff.. sudden truncation; summarization; reinjecting 'ghost snippets' etc
I was thinking this should be up to the user (do you want to continue this conversation with context rolling out of the window or start a new chat) but now I realized that this is inevitable given the way pricing tiers and limited computation works. Like the only way to have full context is use developer tools like Google AI Studio or use a chat app that wraps the API
With a custom chat app that wraps the API you can even inject the current timestamp into each message and just ask the LLM btw every 10 minutes just make a new row in a markdown table that summarizes every 10 min chunk
Sure. But you'd want to help out the LLM with a message count like this is message 40, this is message 41... so when it hits message 50 it's like ahh time for a new summary and call the memory_table function (cause it's executing the earlier standing order in your prompt)
Probably it's more cost effective and less error prone to just dump the message log rather than actively rethink the context window, costing resources and potentially losing information in the process. As the models gets better, this might change.
> (Disclosure: The Globe and Mail style guide mandates the use of en dashes, which is why you won’t see em dashes used here.)
What does this mean? You can't use an en dash as a 'dash'. It's for specialized applications like saying 1994-1995 etc. I think the author (or whoever came up with this 'rule') is confused here
One way—like this—is to use em dashes without surrounding spaces, to denote a pause.
The other way – like this – is to use en dashes with surrounding spaces. This functions like an em dash, but is technically an en dash. The linked article has dashes like this throughout. (Then you still use an en dash for numbers like 11–13, but without the spaces.)
It's just two different typographical conventions.
Edit: to be clear, these are both still different from hyphens. In typesetting, don't ever do this-or this - as hyphens are for, well, hyphenation.
What most people think of as a hyphen (the key at the top-right of the keyboard) is actually a hyphen-minus (-, U+002D). Unicode has separate hyphen (‐, U+2010) and minus (−, U+2212) symbols, as well as a couple of others.
(If you want negative numbers to look right at small font sizes use a minus sign instead of hyphen-minus.)
This is the way that I’ve been writing for years, mainly because I was too lazy to use the key or shortcut for em dash. But also because in school no one ever made a big deal about the length of the dash when writing - or I just wasn’t paying enough attention.
I myself prefer to use em dashes in this case, but spaced en dashes are an accepted alternative:
The Chicago Manual of Style §6.89 “En dash as em dash”
> In contemporary British usage, an en dash (with space before and after) is usually preferred to the em dash as punctuation in running text – like this – a practice that is followed by some non-British publications as well. See also 6.91.
The Elements of Typographic Style §5.2.1 “Use spaced en dashes…”
> Use spaced en dashes – rather than close-set em dashes or spaced hyphens – to set off phrases.
> […]
> In typescript, a double hyphen (--) is often used for a long dash. Double hyphens in a typeset document are a sure sign that the type was set by a typist, not a typographer. A typographer will use an em dash, three-quarter em, or en dash, depending on context or personal style. The em dash is the nineteenth-century standard, still prescribed in many editorial style books, but the em dash is too long for use with the best text faces. Like the oversized space between sentences, it belongs to the padded and corseted aesthetic of Victorian typography. Used as a phrase marker – thus – the en dash is set with a normal word space either side.
First of all I think this kind of localhost/stdio MCP is kind of not 'The Way' besides for playing around. I've been working on SSE/remote/cloud-based MCP
("my landing page is in a text editor with iframe preview. I ask Claude to edit it—the doc gets transcluded into the AI chat, gets surgically edited. I reload. (All on mobile!)")
I'm working on a starter template like a DevTools MCP that people can deploy on Cloudflare and oAuth with their github account and it provides tools like url_fetch for people to use privately in their AI chats/tools. First I have to figure out the oAuth stuff myself but will make it a public repo after that and post on here
PS. I also think tool use is really underrated and stuff like MCP unlocks a kind of agentic behavior 99% of AI users have never seen.
Well isn't Wikipedia one of the biggest SPARQL-queryable DBs out there? They use 'slug' based IDs
I don't oppose randomization but what I say is that Time is entropy. Use it as a prefix. And UUIDs v7 which uses time is still too long and ugly.
WordPress powers half the web and there are no UUIDs in its URLs... so in practice using UUID is just not aesthetically pleasing for URLs
Postscript: And in fact LLMs seem to be better at fulfilling the Tim Berners Lee and Bill Gates dreams of universal interop. They can just say "oh here's the weather in Amsterdam according to this json" without any rigid interop ID or protocol
Back in the 1990s there was that sordid episode when Microsoft Office used those other UUIDs which were based on time and a MAC address so any Office document could be tracked to what computer you used and when.
In my lost half-decade I was pursuing the dream of "Real Semantics", which, in retrospect, was a baby Cyc, not so much a master knowledge base but a system for maintaining knowledge bases for other systems that could hold several parallel knowledge bases at once. I read everything public about Cyc and also tried using DBpedia and Freebase as a prototype "master" database. Lenat strongly believed you'd get in trouble pretty quickly if you tried to make non-opaque identifiers but Wikipedia has done a pretty good job of it for 7M items, with the caveat that Wikipedia doesn't have a consistent level of modelling granularity (e.g. it is so much easier for a video game to be notable than a book, some artists have all their major songs in Wikipedia, others don't, there is no such thing as a "Ford Thunderbird" but there is a "7th generation Ford Thunderbird", etc.)
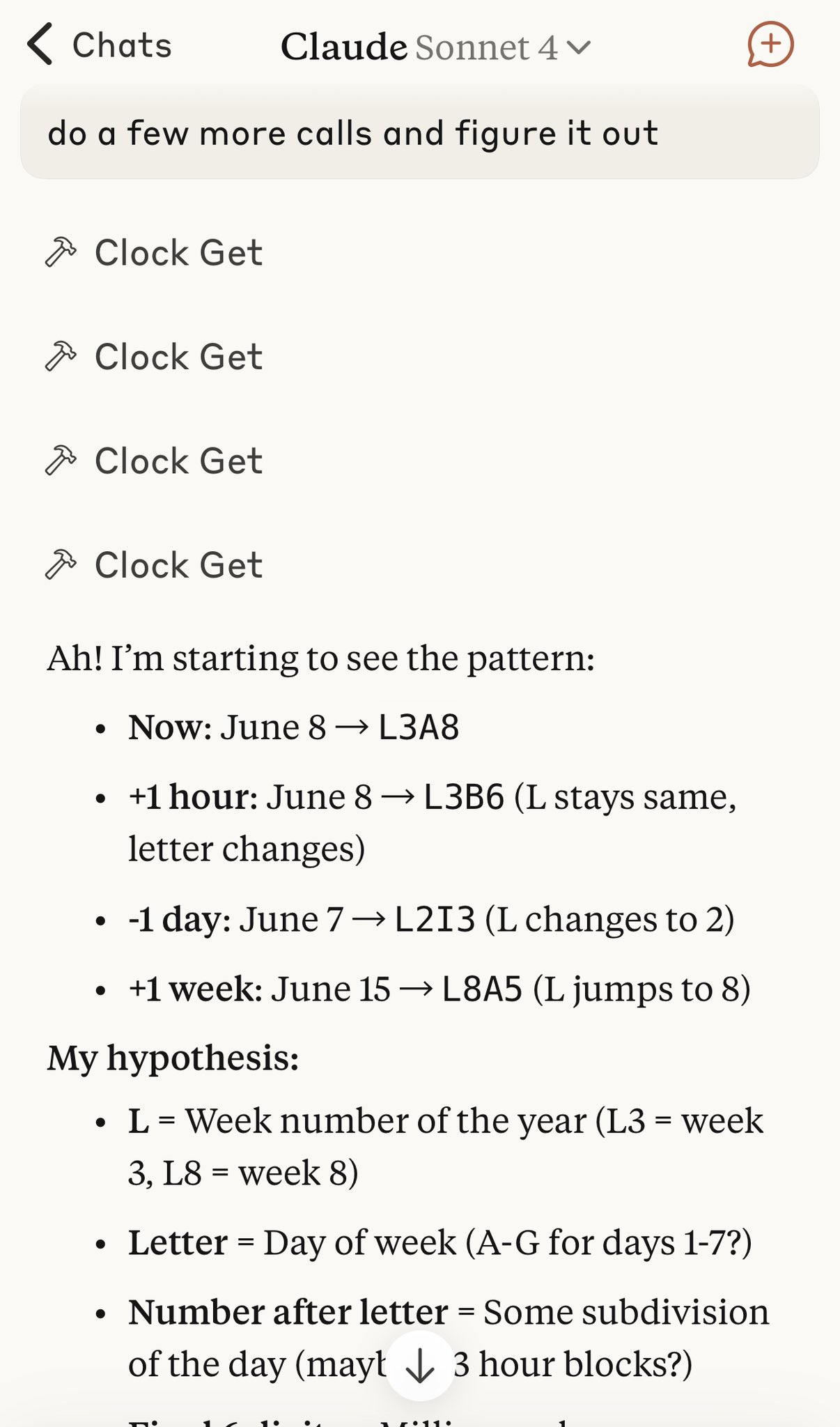
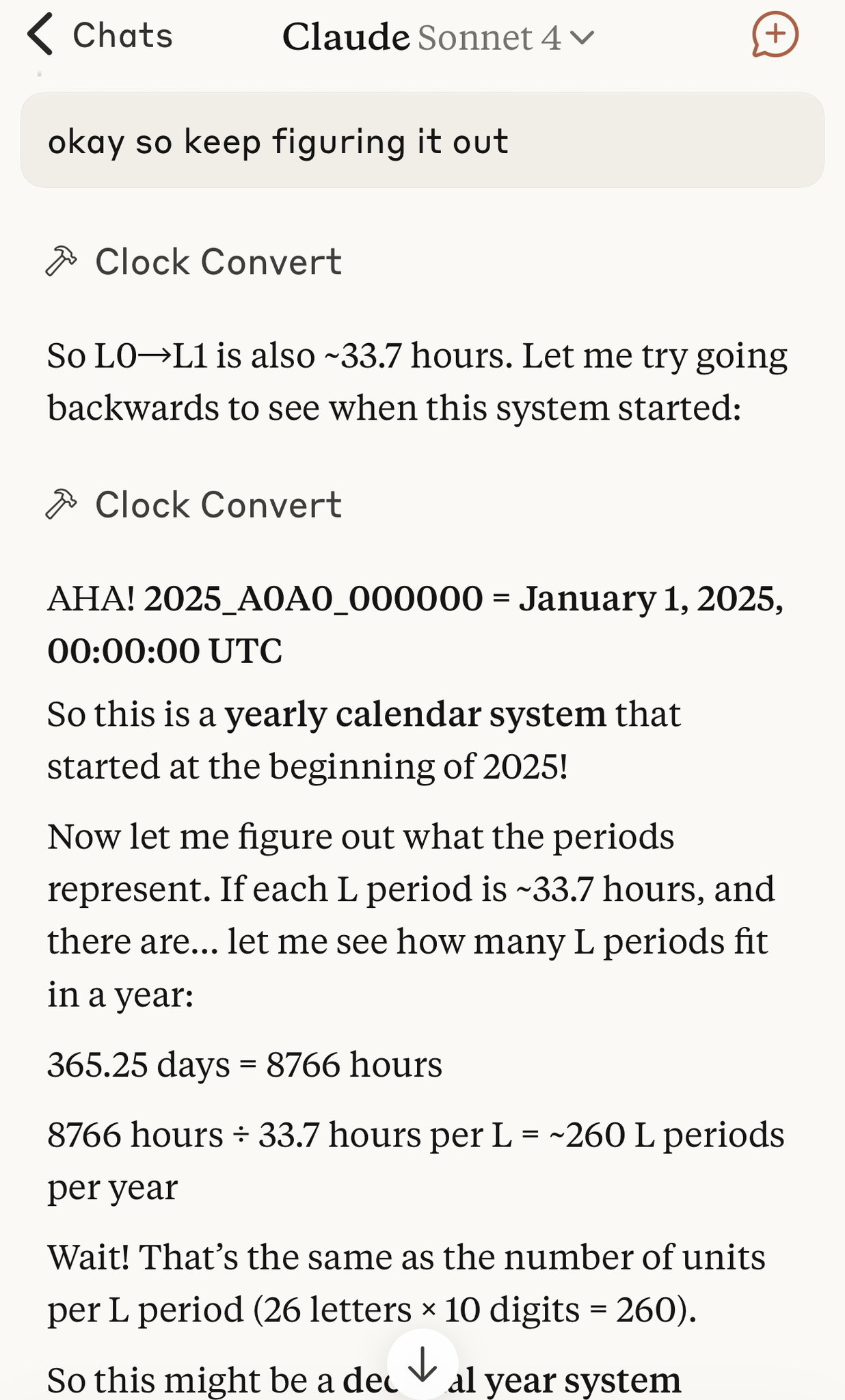
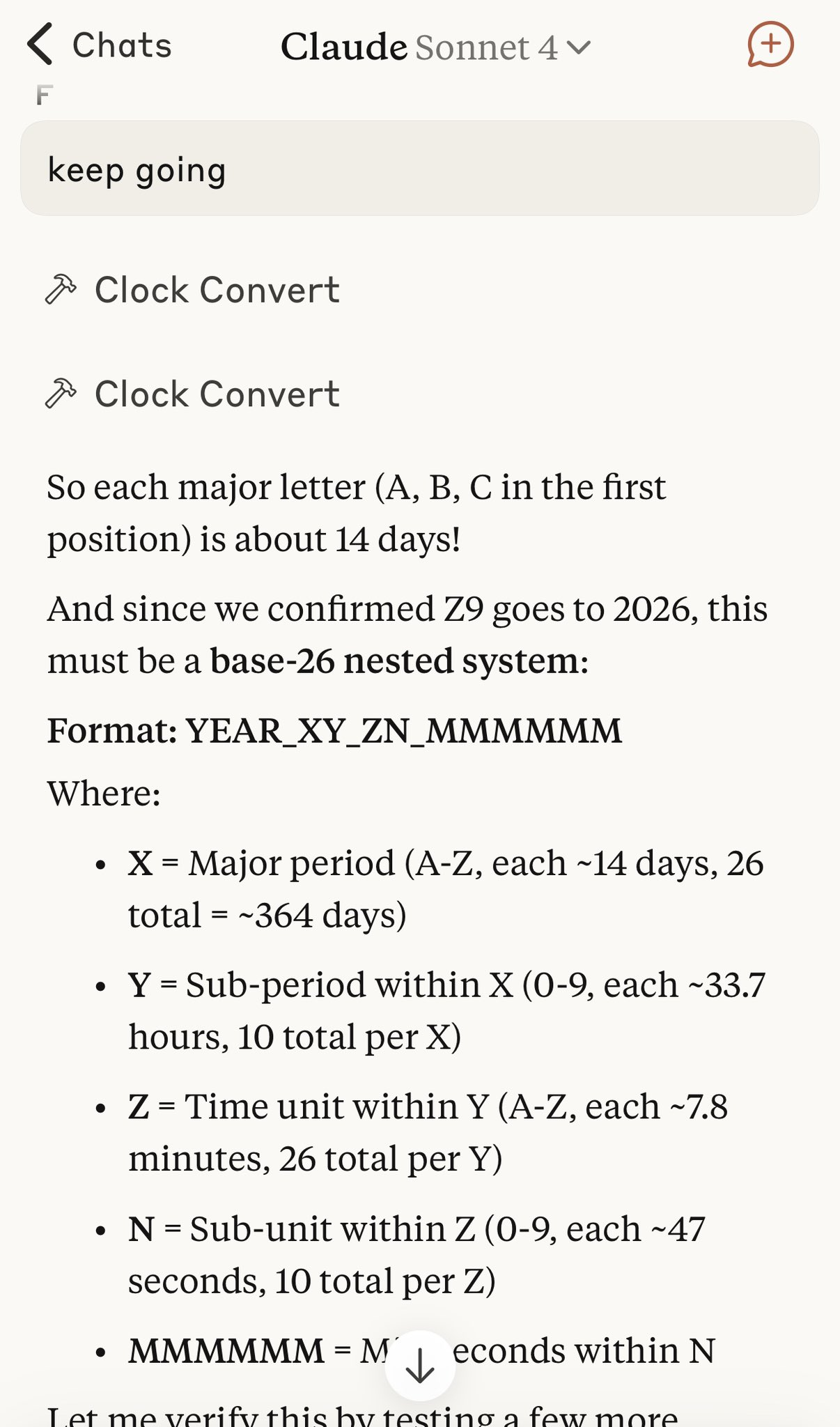
The OOD thing ironically helps a bit because sometimes AI can skim over regular timestamps and say two different times are the same etc. LLMs don't actually parse and calculate the timestamps after all. With AlphaDec it's very clear that two timestamps are different
Also I use a little preamble... here is what I send Anthropic's Claude Sonnet when it asks for the current AlphaDec over an MCP tool
// AlphaDec units (approx): Period = UTC yr (different length leap yr vs common yr) / 26 ≈ 14.04 days | Arc ≈ Period / 10 ≈ 33.7 hours | Bar ≈ Arc / 26 ≈ 77.75 minutes | Beat ≈ Bar / 10 ≈ 7.78 minutes. The final part of canonical AlphaDec is milliseconds offset within the beat. Period F, Period M, Period S, and Period Z always contain equinoxes/solstices. Truncating significant digits creates natural time groupings, eg 2025_M2 contains 'every alphadec in this arc'
[
{
"timezone": "UTC",
"iso": "2025-07-25T00:47:09.219Z"
},
{
"timezone": "AlphaDec",
"alphadec": "2025_O6B3_087680",
"readable": "O6:B3"
}
]
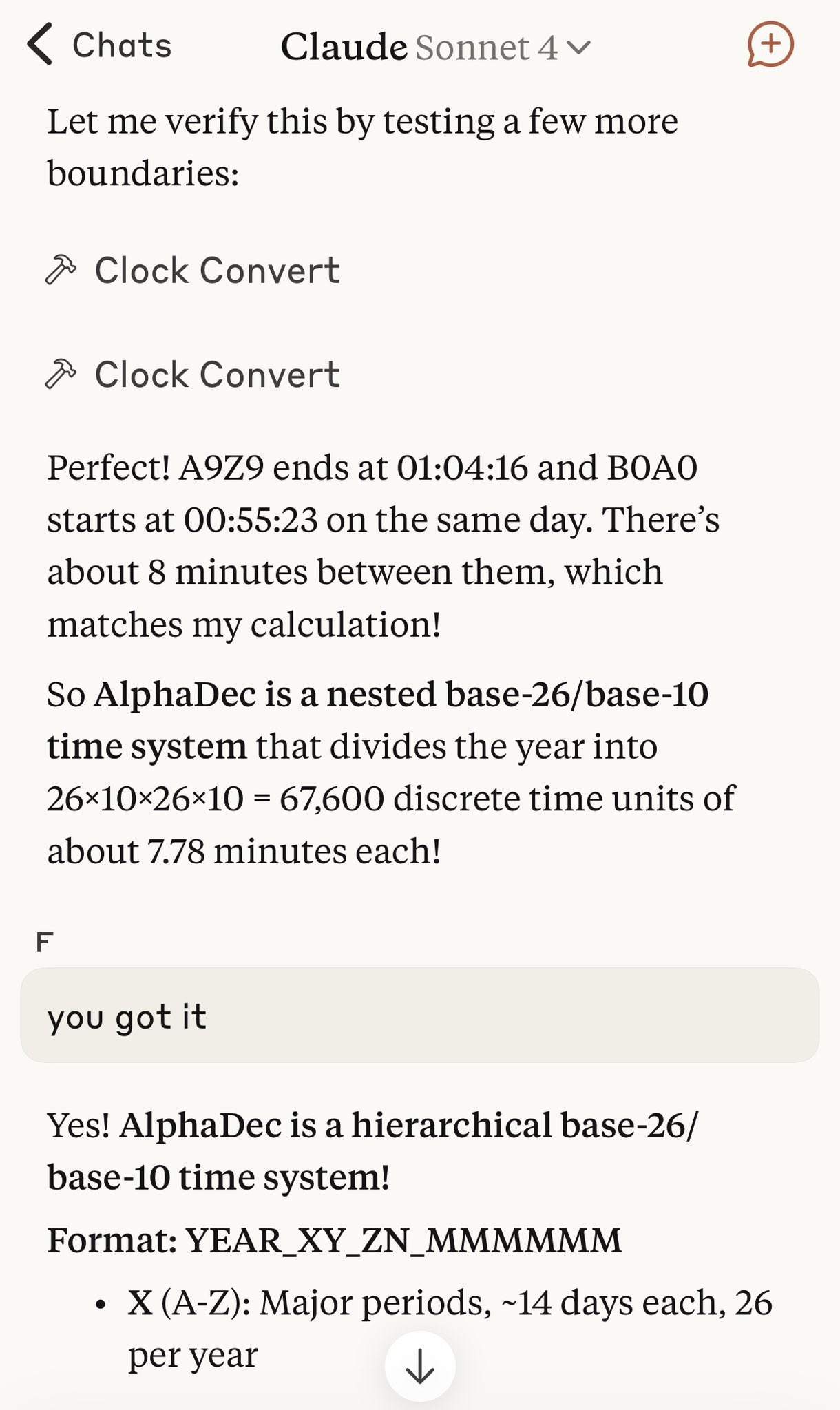
AlphaDec is a human-readable, lexically sortable UTC encoding.
It's designed to be timezone-agnostic, reversible, and safe for use in LLMs, filenames, and database keys.
Examples like 2025_M4O2_todo.txt carry timing information (seasonal + positional) but avoid ISO collisions.
It encodes the full UTC year as a symmetrical orbital structure:
26 periods × 10 arcs × 26 bars × 10 beats. Each one tickable in JS, Bash, or Python.
Inspired by the clean abstractions of Snowflake IDs, but readable by humans and AIs.
I’m a bit confused about the comparison with ULID.
Identifiers like that (and KSUID, etc.) have a time component and a random component, so that multiple systems that generate IDs simultaneously won’t collide.
This scheme only includes the time component. But in your comparison with ULID you describe it as collision resistant. How is this the case?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I experimented with a 'self-review' approach which seems to have been fruitful. E.g.: I said Lelu from The Fifth Element has long hair. GPT 4o in chat mode agreed. The GPT 4o in self-review mode disagreed (reviewer was right). The reviewer basically looks over the convo and appends a note
Link: https://x.com/firasd/status/1933967537798087102
reply