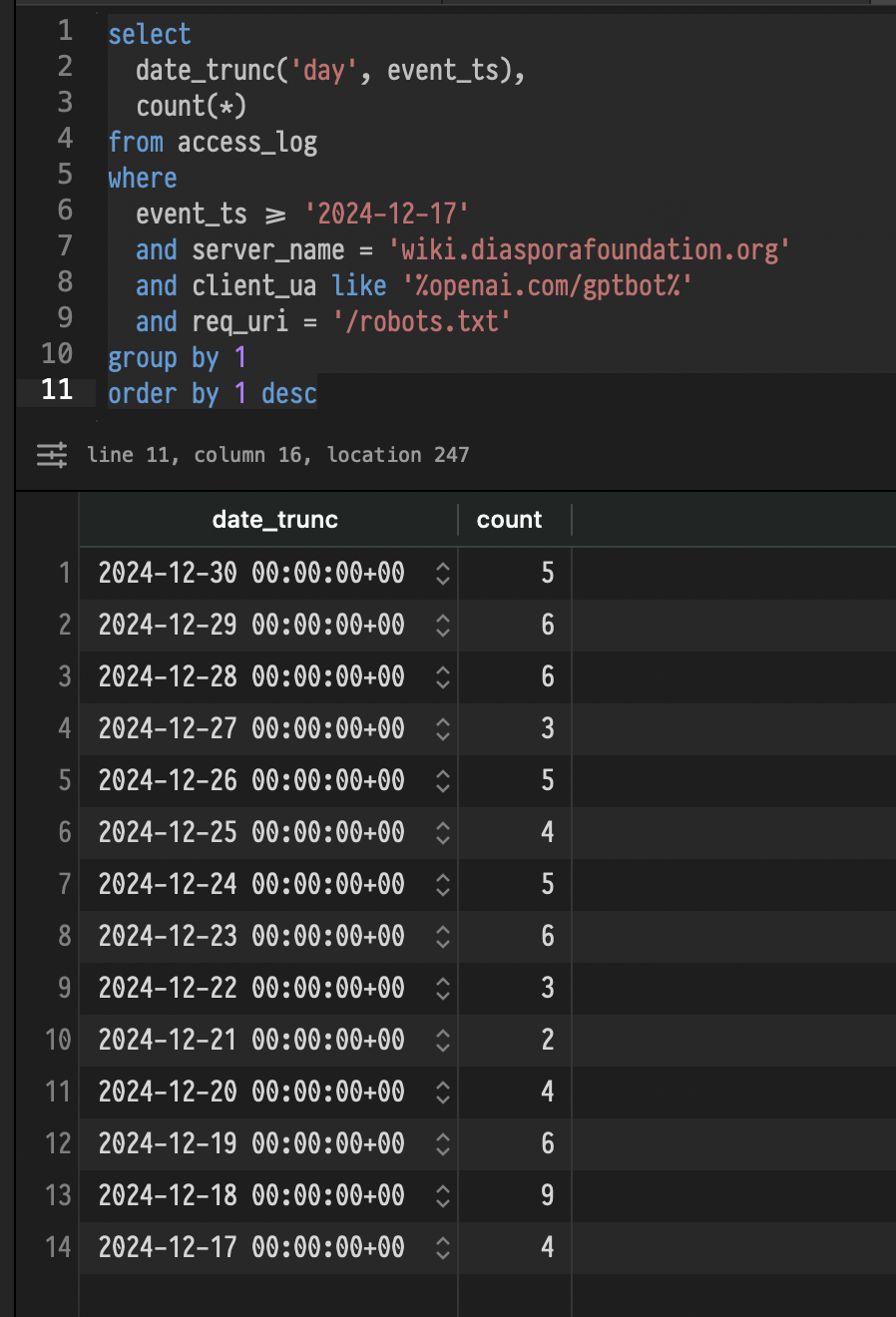
the robots.txt on the wiki is no longer what it was when the bot accessed it. primarily because I clean up my stuff afterwards, and the history is now completely inaccessible to non-authenticated users, so there's no need to maintain my custom robots.txt.
:/ Common Crawl archives robots.txt and indicates that the file at wiki.diasporafoundation.org was unchanged in November and December from what it is now. Unchanged from September, in fact.
they ingested it twice since I deployed it. they still crawl those URLs - and I'm sure they'll continue to do so - as others in that thread have confirmed exactly the same. I'll be traveling for the next couple of days, but I'll check the logs again when I'm back.
of course, I'll still see accessed from them, as most others in this thread do, too, even if they block them via robots.txt. but of course, that won't stop you from continuing to claim that "I lied". which, fine. you do you. luckily for me, there are enough responses from other people running medium-sized web stuffs with exactly the same observations, so I don't really care.
Here's something for the next time you want to "expose" a phony: before linking me to your investigative source, ask for exact date-stamps when I made changes to the robots.txt and what I did, as well as when I blocked IPs. I could have told you those exactly, because all those changes are tracked in a git repo. If you asked me first, I could have answered you with the precise dates, and you would have realized that your whole theory makes absolutely no sense. Of course, that entire approach is mood now, because I'm not an idiot and I know when commoncrawl crawls, so I could easily adjust my response to their crawling dates, and you would of course claim I did.
So I'll just wear my "certified-phony-by-orangesite-user" badge with pride.
Gentleman’s bet. If you can accurately predict the day of four of the next six months of commoncrawls crawl, I’ll donate $500 to the charity of your choice. Fail to, donate $100 to the charity of my choice.
Or heck, $1000 to the charity of your choice if you can do 6 of 6, no expectation on your end. Just name the day from February to July, since you’re no idiot.
I've observed only one of them do this with high confidence.
> how are they determining it's the same bot?
it's fairly easy to determine that it's the same bot, because as soon as I blocked the "official" one, a bunch of AWS IPs started crawling the same URL patterns - in this case, mediawiki's diff view (`/wiki/index.php?title=[page]&diff=[new-id]&oldid=[old-id]`), that absolutely no bot ever crawled before.
"I'm in Europe so I don't have to care because software patents are not enforceable here" isn't the solution. Yes, patent law doesn't apply - but copyright law does, and they very much can take down content that references the spec just based on copyright law alone.
(Also I'd think copyright in EU doesn't normally apply to implementing protocols as it's supposed to grant monopolies of creative expression? but IANAL)
> I'm sure Thread Group would love to stop Google making OpenThread available
Google is a founding member of the Thread Group. OpenThread exists publicly because it's the only widely available implementation that's shipped in a lot of places. Nordic's SDK, for example, uses OpenThread.
OpenThread is built by and for members of the Thread Group, and used by them. It's fairly clear that Google doesn't care much about anyone else.
The second one to their press team sounds super presumptuous, sorry for that, but I found that you kinda have to talk to press teams in that way if you want to get /any/ response at al.
Thanks for being so open and sharing this. I truly hope that this is an oversight on their part and not something intentional, and we're just looking for the right person who can "press the button" and grant you a license.
Looking at https://www.threadgroup.org/thread-group, it seems like they already have some access for free ("Academic" and "Associate"). I'll have to review your blog post to see if you already reviewed those and what the specific issues were.
Edit: I see you did mention their "Implementor" membership level, but I'm not sure which of thier points you need to "implement their IP" that the no-cost memberships lack... "Access to IP rights", maybe?
> Q: Is membership in the Thread Group alone, at any membership level, sufficient to gain and receive royalty-free intellectual property rights (IPR) for Thread technology? A: No, membership at any level is not sufficient to gain and receive royalty-free intellectual property rights (IPR) for Thread technology.
and an Associate membership does not apply because I am not white-labeling or rebranding existing products.
Lawyers have little issue defining blogs like mine as "with commercial interest". I have a side-business, so lawyers could make the argument that I use my blog as advertising. I have a Ko-Fi link in the bottom of one specific site, that's a commercial interest, too.
Unless your blog is "I'm sharing holiday photos and nothing else", there's a lot of instances where it could be define as an outlet with commercial interests.
And, ultimately, I have no desire to spend any time and money on fighting even completely invalid claims. I'd rather spend my time watching cat videos on YouTube instead.
But their licensing doesn't care about commercial interests or lack of there of.
It only reserves right to charge you if you ship a product. And by product they most obviously mean a device and by ship they obviously mean sell (or gift, or possibly rent) to some customers.
All of this sounds like a thunderstorm in a glass of water by people who read too many software licenses.
It's because people read more than one sentence and the very next one is:
"Failure to maintain active Thread Group membership while shipping Thread technology may result in legal action, including but not limited to licensing fees."
Which specifically mentions legal action in reaction to shipping only.
"Membership in Thread Group is necessary to ..." is just a statement of their wishes.
It's like "Sleeping is necessary for good health". It doesn't mean we'll sue you, if you don't sleep.
This issue was caused by Google on their server-side, without any relation to a change in Firefox, so I'm not sure why you feel the need to yell at my Mozilla-colleague.
As a quality control technician, I have several tests, including checking against third party resources for compatibility.
If I were a web browser coder, making sure my software worked with the major websites of the internet would be the FIRST thing to test. I don't release until I know it works.
This exact same mindset is why I make the expensive stuff where I work, and nobody else.
I'm also not yelling. That you think text is yelling is quite something I'll never understand from anyone. Two capitalized words isn't yelling.
You are 100% correct in your assumptions. This isn't my first incident, and it won't be my last. As much as some folks here want to call me an asshole for that, we have a very good understanding of how this ends if we don't lock comments.
FWIW, good on you for managing the signal responsibly.
I have to smirk a bit every time I see the public do this to themselves. The public: "Why are companies never honest? Why is press-release-speak such a space-alien way of communicating?" Also the public: reacts like this when someone takes a simple, clear action and explains it directly.
(And yes, I know I'm guilty of broad-strokes reasoning lumping everyone in as "the public" and anthropomorphizing that entity. In this context, doesn't matter. Only takes a few bad actors to wreck the signal).
{kind=link}